Claude Skills & n8n: Who Owns Orchestration vs Code? (2026)


Table of Contents
- Introduction
- What does splitting orchestration from implementation actually fix in mid-size orgs?
- When should n8n own triggers, connectors, and production execution?
- When should Claude Code and Skills own implementation, tests, and documentation?
- How do teams avoid maintaining the same business process in both a canvas and a repo?
- What operating model stops engineering and automation from blaming each other?
- How do you run Claude Code plus n8n without duplicating logic or slowing delivery?
- What should buyers put in writing in the first 30 days?
- Frequently Asked Questions (FAQs)
Introduction
Here is the buyer-friendly verdict up front: in a real organization, you get the least drama and the most speed when n8n (or a comparable workflow engine) owns orchestration - triggers, connector calls, retries, credentials, and execution history - and Claude Code plus Skills own implementation - the code, prompts, tests, and repo-native documentation that express messy domain logic. The failure mode you are trying to escape is not "we picked the wrong logo." It is two competing sources of truth for the same process - one living in a visual graph, another living in a branch nobody reviewed - so every incident becomes a referendum on who was supposed to know.
This article is about coordination and velocity, not a feature matrix. It is for people who already sense that coding agents and integration workflows are complementary, but need a clear boundary so teams stop re-implementing the same behavior twice and stop arguing about which copy is authoritative. I will walk through what that split buys you, where each tool wins, how duplicate truth creeps in, and a lightweight operating model you can adopt quickly.
Related: Can Claude Code replace n8n? | Claude Code Skills for n8n | Cursor vs VS Code vs Claude Code
What does splitting orchestration from implementation actually fix in mid-size orgs?
Mid-size companies are where the pain shows up first. Enterprise buyers buy platforms with committees; tiny teams can keep everything in one head. In the middle, you have multiple functions touching the same customer journey - sales ops, marketing ops, data, product engineering, IT - and a growing catalog of SaaS tools. Someone stands up n8n because integrations need to move without waiting for a sprint. Someone else adopts Claude Code because shipping and refactoring software got faster. Both are rational.
The problem is conceptual overlap. Both tools can "do automation." Both can call HTTP APIs. Both can embed AI. Without an explicit split, you get shadow implementations: a workflow that posts to Slack and a script that also posts to Slack, each maintained by a different team, each slightly wrong in different ways. Splitting orchestration from implementation means you decide which layer is allowed to mutate production behavior for a given process, and you write that decision down where new hires can find it.
Orchestration answers: when does work run, what systems are touched in what order, what happens on failure, and who can see that it ran. Implementation answers: how do we compute the hard parts, how do we validate inputs, how do we keep behavior stable across refactors, and how do we prove it with tests. When those concerns stay tangled, every change is high coordination cost. When they separate cleanly, n8n stays thin - mostly wiring - and code stays thick - mostly logic - or the reverse for rare cases where the logic is trivial and the graph is the product.
Why do two sources of truth create rework and finger-pointing?
Two truths do not mean "we use two tools." They mean the same business rule is authored twice without a contract between the copies. Example: lead scoring lives partly in an n8n Code node and partly in a service Claude Code generated, and nobody can say which one the revenue team should trust. Incidents expose the gap. Sales says automation broke. Engineering says the workflow bypassed validation. Automation says the API changed. Everyone is partly right because ownership was implicit.
Finger-pointing is a symptom of missing interfaces. A useful split adds an interface: the workflow calls one HTTP endpoint or runs one containerized worker with a versioned artifact. The graph shows the schedule and the fan-out; the repo shows the algorithm. If behavior diverges, you know which side drifted because only one side is allowed to own that behavior.
When should n8n own triggers, connectors, and production execution?
Default n8n ownership when the work is integration-shaped: webhooks from SaaS tools, cron schedules, polling queues, file drops, multi-step fan-out, human handoffs via tickets, and anything where execution traceability matters to people who will never open your repository.
Default n8n ownership when the work is integration-shaped: webhooks from SaaS tools, cron schedules, polling queues, file drops, multi-step fan-out, human handoffs via tickets, and anything where execution traceability matters to people who will never open your repository. n8n is built to answer operational questions: what ran, when, with which payload, and where did it die. That is not a nice-to-have when finance or compliance asks for receipts.
n8n also wins on credential hygiene relative to ad-hoc scripts. Central secret storage, scoped access, and audit-friendly patterns are easier to standardize in a workflow server than across forty laptops running agent-assisted code. Buyers should be honest about governance: if your organization already treats n8n as production infrastructure, new automation should probably land there first unless you have a strong engineering reason not to.
Speed shows up in a specific way. Visual graphs reduce the time to compose known connectors. They do not magically remove the need for careful design, but they lower the activation energy for cross-functional iteration. A marketer can point at a node and say "this step is wrong" without reading TypeScript. That is coordination speed - fewer translation rounds - as long as the graph stays a thin orchestration layer rather than a second application server.
How does visual orchestration improve coordination across non-developers?
Non-developers rarely want to browse git blame. They want a map. A workflow canvas is a shared picture of cause and effect. When something breaks, the picture suggests where to look. When requirements change, the picture supports a conversation: insert a step, branch on a field, add a delay. The risk is that the picture becomes so detailed that it is really a program in disguise. The discipline that preserves coordination benefits is keeping complex logic out of the graph unless it is truly shallow.
Think of n8n as the airport control tower routing planes. It should not redesign the aircraft mid-flight. Claude Code is the hangar where you engineer the aircraft with tests and tooling. If you confuse the roles, you end up with towers full of blueprints and hangars full of traffic controllers - slow, dangerous, and expensive.
When should Claude Code and Skills own implementation, tests, and documentation?
Default Claude Code ownership when the work is software-shaped: branching business rules, data normalization across messy sources, parsing unstructured text, generating or refactoring codebases, writing migrations, and anything you would want code review, CI, and version pins to protect.
Default Claude Code ownership when the work is software-shaped: branching business rules, data normalization across messy sources, parsing unstructured text, generating or refactoring codebases, writing migrations, and anything you would want code review, CI, and version pins to protect. Claude Code accelerates the boring and error-prone parts of that work. It does not remove accountability; it concentrates it in artifacts humans can review.
Skills (in the Anthropic sense) belong in this layer because they package how work should be done inside the agent-assisted development loop: repeatable instructions, checklists, and resources that keep outputs consistent across sessions and teammates. Skills are not a substitute for a workflow runtime. They are a way to stop every developer from re-prompting the same architecture rules from scratch.
Putting implementation in a repo also makes diffs legible. That matters for organizational speed. When behavior changes, you want a PR or a tagged release, not a silent edit in a shared workflow that nobody diffed against production. This is where buyers often under-invest: they celebrate how fast a graph is to edit, then discover they cannot explain what changed last Tuesday.
Can Claude Skills replace n8n nodes for SaaS integrations?
Usually no for production integration, and that is the point. n8n nodes encode maintained adapter knowledge - auth flows, field mappings, pagination quirks - for a specific execution engine. Skills teach Claude how to reason about tasks and follow your conventions. You might use a Skill to generate an OpenAPI client or draft n8n JSON, but the ongoing, monitored calls to Salesforce or HubSpot still belong in the orchestration layer unless you are deliberately running a custom service with the same operational guarantees.
The hybrid pattern is straightforward: n8n performs the integration call; your service (written or refined with Claude Code) performs interpretation and decisioning if the decisioning is non-trivial. The anti-pattern is duplicating the integration in both places "because the agent was faster today." Speed without a boundary becomes debt tomorrow.
How do teams avoid maintaining the same business process in both a canvas and a repo?
Prevention is simpler than cure. Adopt a rule: every non-trivial branch, calculation, or policy exists in exactly one artifact. If it lives in code, the workflow calls code. If it lives in the workflow, the repo does not re-encode it. "Non-trivial" is a judgment call, so teams should define a threshold - for example, anything beyond a single conditional on a field - and revisit quarterly.
Practical contracts help. Expose a small API surface: POST /process-lead, POST /summarize-ticket, whatever matches your domain. Version it. Log request IDs through n8n so executions correlate with application logs. Document inputs and outputs in one page both teams trust. When someone proposes a new Code node with fifty lines of JavaScript, treat that as a signal to promote logic into a proper module with tests instead.
Another subtle duplicate is prompt text. If prompts live only inside an n8n AI node, engineers will copy them into repos for local experiments, and now you have drift. Better: prompts live in git as files, and n8n reads them from a release artifact or a pinned URL. The orchestration layer executes; the repo authors the prompt. Same idea for JSON Schemas and tool definitions used by agents.
What operating model stops engineering and automation from blaming each other?
Borrow from RACI without drowning in paperwork. For each critical workflow, name one accountable owner for production behavior, one primary builder in n8n, and one primary owner for any service code it calls. The magic is not the labels. It is that on-call and escalation routes map to those names. When the pager fires, nobody should need a committee to decide whether the workflow or the service is the first suspect.
Add a lightweight interface review for changes that cross the boundary. If a workflow adds a new field, the service owner acknowledges schema compatibility. If a service changes response shape, automation gets a heads-up before deploy. This can be a ten-minute checklist attached to PRs and workflow export notes. The goal is shared visibility, not bureaucracy.
Finally, measure the right things. Count duplicate implementations discovered in incidents. Track mean time to identify whether failure was orchestration versus implementation. If those metrics improve after you split responsibilities, you have evidence for leadership beyond anecdote.
How do you run Claude Code plus n8n without duplicating logic or slowing delivery?
Treat Claude Code as acceleration for the repo side of the hybrid stack. Use it to scaffold handlers, write tests, migrate brittle scripts, and document interfaces. Treat n8n as the place production wiring is visible. When a new use case appears, the fastest path is often: sketch the graph for triggers and destinations, stub an HTTP node toward a new endpoint, then let Claude Code implement the endpoint with tests.
Avoid the trap of letting the agent directly edit production workflows without the same safeguards you would expect from human admins. Agents are fast; mistakes are fast too. Prefer generating artifacts - workflow JSON, OpenAPI specs, infrastructure snippets - that humans review and import through normal change control.
For AI inside the pipeline, be explicit about where inference runs. A pattern that scales: n8n gathers context and calls a single model gateway you control, with rate limits, logging, and redaction rules. Claude Code helps maintain that gateway code. n8n should not become a maze of twenty experimental prompts nobody owns. Centralize model configuration; distribute business steps.
Picture a concrete lead-routing flow so the split is not abstract. n8n receives the webhook, validates a shared secret, normalizes the payload shape, and enqueues work or calls your service. The service applies territory rules, deduplication, and enrichment that would be painful to test inside a graph. If sales changes a threshold, engineers merge a PR and deploy; automation does not fork a second copy of the rule in a Code node "just for this week." The workflow still changes when connectors or schedules change - but policy stays where diffs and tests live.
What should buyers put in writing in the first 30 days?
If you are evaluating or rolling out this stack, document five decisions early. First, which system is the system of record for running integrations in production. Second, where business logic above X complexity must live - almost always a repo-backed service. Third, how credentials are stored and rotated for both n8n and any custom code. Fourth, how prompts and schemas are versioned so AI steps do not fork silently. Fifth, the escalation path when a workflow and a service disagree.
Share that one-pager with engineering, ops, and any citizen automators. The point is not perfection. It is shared vocabulary. Once everyone agrees that the graph is the control plane and the repo is the implementation plane - or the documented exception where the opposite is true - you stop paying the tax of duplicated truth.
This hybrid is not theory. It is how you keep coordination fast for people who think in processes and implementation fast for people who think in code, without letting either side accidentally become the other's hidden database of business rules.
Frequently asked questions
Quick answers on the topics covered in this article.
Use both for different layers: n8n for orchestration (triggers, connectors, retries, execution history) and Claude Code for building or refactoring the code behind non-trivial logic. Picking only one usually forces you to fake either operations features or software discipline.
Orchestration is when work runs, which systems it touches, and how failures are handled in production. Implementation is the algorithms, validation, data transforms, and tests that determine correct outcomes. Splitting them reduces duplicate business rules.
Skills standardize how Claude-assisted work happens (instructions, resources, repeatable procedures for developers). n8n workflows run scheduled and event-driven integrations in production with operational visibility. They complement each other; Skills do not replace n8n's runtime.
Author each non-trivial rule in one place only. If logic lives in code, workflows call that code through a stable API. If logic stays in the workflow, do not copy it into repositories. Version prompts and schemas from git when AI steps need consistency.
Because ownership and interfaces were implicit. Name accountable owners for the workflow and the service, log correlation IDs across both, and review cross-boundary changes so failures have an obvious first place to look.
Yes, if you centralize model access behind policies: rate limits, logging, redaction, and pinned prompts or schema files. Use n8n to orchestrate the call; use engineering practices to govern model configuration and secrets.
When the logic is short, stable, and unlikely to need tests beyond manual checks - for example, simple field mapping or a single guard clause. If it grows or branches heavily, promote it to reviewed code with CI.
No. It speeds up implementation and maintenance, but production still needs review, deployment, monitoring, and accountability. The org chart does not disappear because the agent types fast.
Often within weeks if you limit scope to a few critical workflows, write the five decision rules on one page, and enforce a single integration surface between graph and code. Depth beats breadth early.
Letting the same behavior be edited independently in a canvas and a repo, which guarantees drift, rework, and blame in incidents. Pick an authoritative home for each kind of change and stick to it.
Share this article
Related workflows
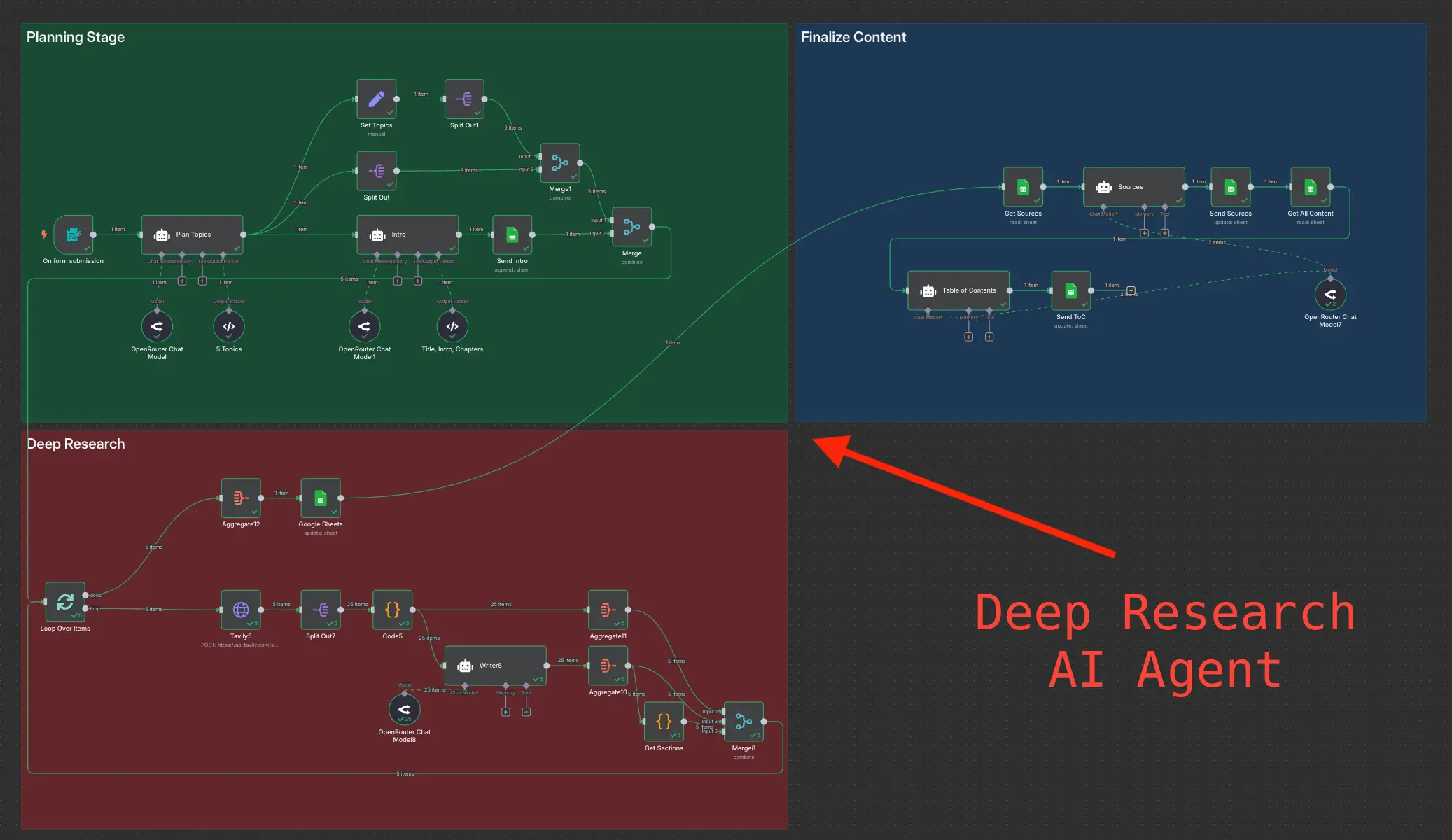
Daily Validated Business Ideas using n8n and Upwork
Deep Research using n8n automation to generate report using Tavily