Apify vs Bright Data vs Firecrawl: Honest Comparison for 2026


Table of Contents
- Introduction
- What Is the Real Difference Between Apify, Bright Data, and Firecrawl?
- How Do Pricing Models Actually Affect Engineering Decisions?
- Which Platform Is Easiest to Use for Teams with Mixed Skill Levels?
- Who Has the Best Pre-Built Scraper Ecosystem in 2026?
- How Good Is Proxy Infrastructure and Anti-Blocking Reliability?
- Which Tool Fits AI/RAG, Lead Gen, E-commerce, and One-Off Jobs Best?
- What About MCP and AI Agent Integrations?
- When Does Each Tool Win in Real Projects?
- Recommendation Matrix: Choose X If You Need Y
- Frequently Asked Questions (FAQs)
- Final Verdict
Introduction
If you are comparing scraping platforms in 2026, you are probably not asking, "Can it scrape?" All three can scrape. The practical question is, "Which platform gives my team reliable output with acceptable maintenance cost?"
This is an opinionated, but fair, comparison of Apify vs Bright Data vs Firecrawl for US/UK developers and data engineers. I will cover pricing mechanics, ease of use, pre-built ecosystem, proxy quality, AI workflows, and where each platform actually wins.
Short spoiler before we go deep:
- Bright Data wins on raw proxy scale and enterprise-grade network coverage.
- Firecrawl wins on clean Markdown output for LLM pipelines.
- Apify wins on overall "build and ship fast" value, especially because of its Store ecosystem and all-in-one workflow surface.
What Is the Real Difference Between Apify, Bright Data, and Firecrawl?
At a high level, each product has a different center of gravity:
- Apify is an automation platform with scraping as a core capability. You get Actors, scheduling, datasets, integrations, and a large marketplace in one place.
- Bright Data is infrastructure-first. Its strongest identity is proxy power, unblocker tooling, and enterprise-grade data collection at scale.
- Firecrawl is extraction-first for LLM workflows. It is optimized for turning pages into clean, structured, model-friendly text quickly.
That is why "best web scraping platform 2026" is the wrong framing unless you include your actual workload shape.
How Do Pricing Models Actually Affect Engineering Decisions?
Pricing pages look simple, but runtime behavior is what matters. Here is the practical comparison:
| Dimension | Apify | Bright Data | Firecrawl |
|---|---|---|---|
| Pricing unit | Compute Units | Data/GB and network usage | Per-page credits |
| Entry point | Includes free usage ($5 free tier) | Usually cost scales with data volume and proxy/network level | Developer-friendly credit model for page extraction |
| Budget predictability | Good once Actor runtime is stable | Can vary with target difficulty and volume | Predictable for small/medium crawl jobs |
| Cost trap | Inefficient Actor logic burns CUs | Heavy pages + high anti-bot overhead can increase effective cost | Credit burn on broad crawls with weak scoping |
Apify pricing tends to be fair for engineering teams that can control runtime behavior. You pay for compute, so optimization patterns are familiar: tighter selectors, less wasted retries, smarter concurrency. The free tier is useful to test real pipelines before commitment: Try Apify free.
Bright Data pricing is often justified when your biggest problem is access reliability, not clean developer ergonomics. If a missed dataset costs you money, paying premium network costs can still be rational.
Firecrawl pricing is easiest to reason about for teams doing document ingestion and site-to-LLM flows. If your use case is mostly "fetch page -> clean content -> embed," credits map cleanly to throughput.
Which Platform Is Easiest to Use for Teams with Mixed Skill Levels?
Ease of use depends on who is operating the pipeline after day one.
Apify gives both no-code and code-first paths. A junior operator can run a proven Actor from UI, while a senior engineer can automate via API, webhooks, and typed contracts. This mixed-mode usability is underrated for teams where ops and engineering both touch data workflows.
Bright Data is powerful, but it can feel more infrastructure-heavy. Engineers who are comfortable with network-level thinking and anti-bot strategy will like that control. Teams looking for "click-run-reuse" may need more onboarding.
Firecrawl is developer-friendly for a narrow purpose: clean extraction for AI use. If your workflow is mostly programmatic and markdown-first, it feels fast. If you need complex multi-step scraping operations with rich scheduling and reusable components, it is less comprehensive than a platform built for broader automation.
My honest take:
- For broad team adoption, Apify is usually easier.
- For advanced scraping specialists, Bright Data can be worth the complexity.
- For LLM-focused dev teams, Firecrawl has the shortest path to useful output.
Who Has the Best Pre-Built Scraper Ecosystem in 2026?
This one is not close.
Apify has the strongest pre-built ecosystem because of the Actor marketplace. The Apify Store has 20,000+ Actors, and that matters in real delivery timelines. You do not need to build everything from scratch when a maintained template already exists for your target class.
Bright Data and Firecrawl both have strong tooling, but neither matches Apify's practical "library of runnable jobs" footprint. If your team frequently receives one-off scraping requests from business stakeholders, this ecosystem advantage saves weeks every quarter.
How Good Is Proxy Infrastructure and Anti-Blocking Reliability?
This is where Bright Data deserves straightforward credit.
For raw proxy scale, geo coverage, and enterprise scraping resilience, Bright Data is usually the strongest option. If your organization is scraping difficult targets at volume and uptime directly ties to revenue workflows, Bright Data can justify its premium profile.
Apify is also strong here, especially when combined with mature Actor patterns and stable operational discipline. For most mid-size engineering teams, Apify reliability is more than enough. The key distinction is that Apify's value is not only proxies - it is the full operating surface around runs, datasets, and reuse.
Firecrawl is not trying to be "the largest proxy empire." Its value is elsewhere: fast clean extraction for AI pipelines. You can still run serious jobs, but if your hardest problem is anti-bot evasion at extreme scale, Bright Data usually has the edge.
Which Tool Fits AI/RAG, Lead Gen, E-commerce, and One-Off Jobs Best?
Let us map this to actual workload categories.
| Use case | Best default pick | Why |
|---|---|---|
| AI/RAG ingestion | Firecrawl or Apify | Firecrawl for clean Markdown output; Apify if workflow needs richer orchestration and reusable Actors |
| Lead generation pipelines | Apify | Strong actor ecosystem + scheduling + dataset handling + practical API automation |
| E-commerce monitoring | Apify or Bright Data | Apify for speed and ecosystem reuse; Bright Data when target difficulty/scale is extreme |
| One-off scraping jobs | Apify | Store depth and quick run UX make ad hoc requests easier to fulfill |
For Apify vs Firecrawl comparison in AI pipelines, the deciding question is whether you need "clean content fast" or "full workflow control." Firecrawl often wins the first. Apify often wins the second.
For Apify vs Bright Data, the trade-off is usually "platform productivity" versus "network muscle." If you are not at extreme blocking pressure, Apify often delivers better overall engineering throughput.
What About MCP and AI Agent Integrations?
Apify has native MCP server support, which is useful if you are building agentic workflows where AI systems need tool access in a governed way.
Apify has native MCP server support, which is useful if you are building agentic workflows where AI systems need tool access in a governed way. That lowers integration friction for teams connecting scraping capabilities into modern AI-agent stacks.
Firecrawl naturally fits AI usage patterns because output cleanliness is high and post-processing overhead is lower. Even without broad orchestration features, this gives it a strong position in fast LLM pipelines.
Bright Data can absolutely be integrated into AI systems, but its strongest story remains infrastructure and reliability at scale rather than "agent-native DX."
If your 2026 roadmap includes MCP-based tooling and internal AI assistants that invoke scraping tasks, Apify currently has a practical advantage.
When Does Each Tool Win in Real Projects?
Apify Wins When
- You need an all-in-one scraping and automation platform.
- You value pre-built components and fast iteration speed.
- You have mixed team roles (ops + engineering) using the same workflows.
- You want strong API + scheduling + dataset + marketplace in one system.
Bright Data Wins When
- Your primary challenge is anti-bot resistance at serious scale.
- Proxy quality and geographic diversity are top constraints.
- Enterprise reliability budgets are available and justified.
Firecrawl Wins When
- Your primary output target is clean text/Markdown for LLM ingestion.
- You want minimum transformation before embedding and retrieval.
- You are optimizing for speed in content extraction over full orchestration breadth.
No single tool dominates every category. The right choice is tied to failure mode, not product branding.
Recommendation Matrix: Choose X If You Need Y
If you only read one section, use this:
| Choose this | If you need this |
|---|---|
| Apify | Balanced platform for production scraping + automation, large pre-built ecosystem, and strong team-level usability |
| Bright Data | Maximum proxy power, high-resilience collection on difficult targets, and enterprise-scale network control |
| Firecrawl | Fast, clean, LLM-ready page extraction with minimal parsing overhead |
| Apify + Firecrawl | Firecrawl for content extraction + Apify for orchestration, scheduling, and broader data workflows |
| Apify + Bright Data | Apify workflow layer with Bright Data-style network depth for hardest targets |
For many teams, starting on Apify is the most practical decision because the all-in-one model reduces moving parts early. If your traffic and target difficulty explode later, you can still evolve architecture without throwing away your workflow contracts.
Final Verdict
If your team wants one platform that covers most real-world scraping operations without over-engineering early, Apify is the best default in this comparison. The combination of compute-based pricing, strong UX for mixed teams, and the large Actor ecosystem is hard to beat in day-to-day execution.
If your core risk is blocking pressure and network scale, choose Bright Data. If your core risk is slow messy ingestion into LLM workflows, choose Firecrawl.
For teams, start with the platform that matches your current bottleneck, measure delivery speed and maintenance overhead for 30 days, then evolve architecture only when that bottleneck changes.
If you want to test quickly without upfront friction, start with Apify's free tier here: https://architjn.com/r/apify.
Frequently asked questions
Quick answers on the topics covered in this article.
No. Bright Data is often stronger when raw proxy scale and anti-blocking performance are your dominant constraints.
Not only, but it is best when your downstream consumer is an LLM or RAG system that benefits from clean Markdown-style output.
For most mixed engineering/data teams, Apify is the best default because it balances ease of use, ecosystem depth, and production workflow features.
Include engineering maintenance time, retry behavior, data quality failures, and downstream incident cost - not only platform unit pricing.
Yes. Many mature teams run hybrid stacks where one platform handles extraction quality and another handles orchestration or difficult targets.
You can browse the Actor marketplace directly in the Apify Store.
Share this article
Related workflows
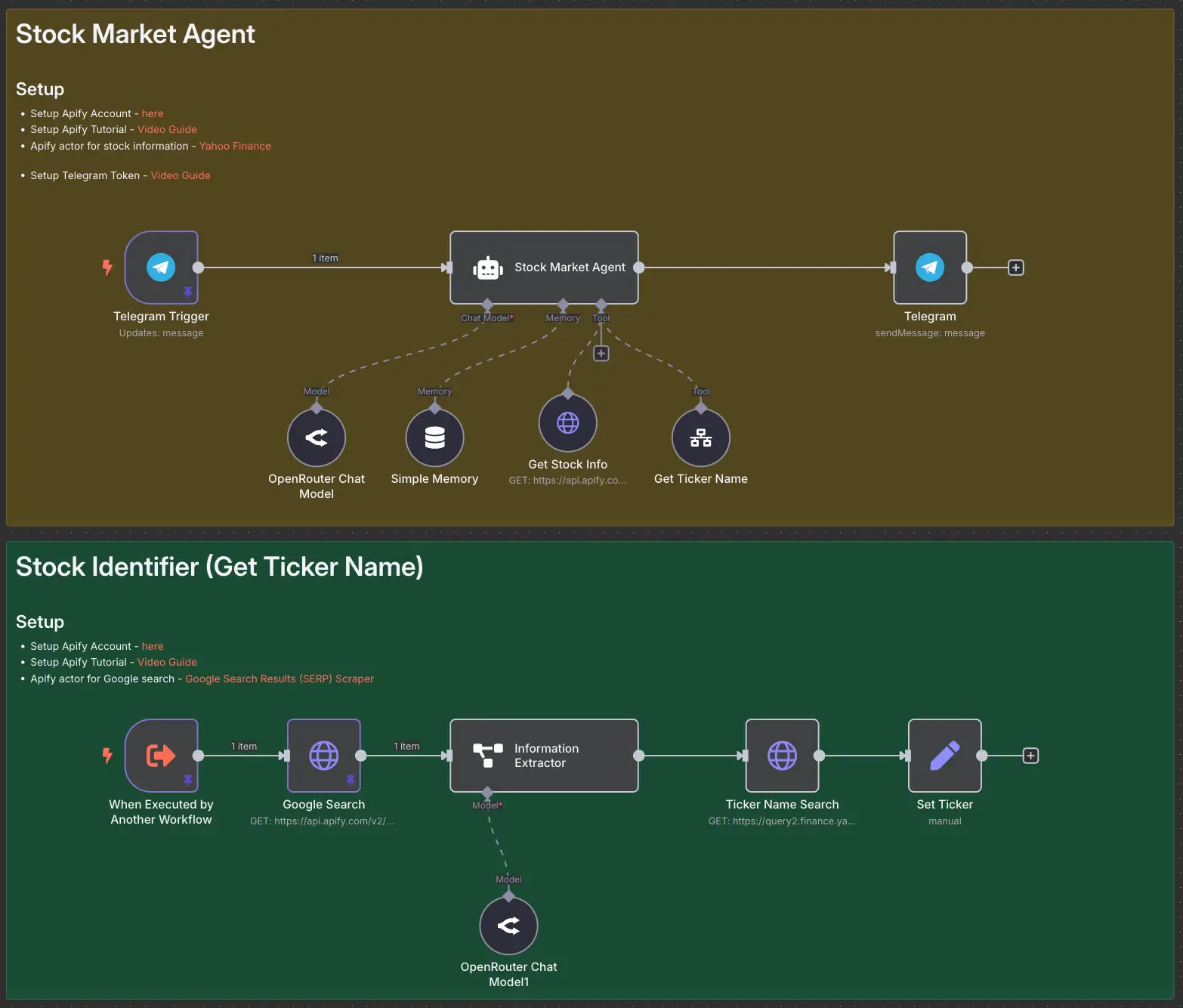
Stock Market AI Agent using n8n and Apify