Claude Fable 5 Migration: Move Off Opus 4.8 Without Drift


Table of Contents
- Introduction
- What changes when you move from Opus 4.8 to Claude Fable 5?
- Why is a model swap not a drop-in replacement?
- What does a Claude Fable 5 migration checklist look like?
- How do you handle refusal and fallback differences?
- When should you not migrate a workflow at all?
- Which prompt and settings tweaks reduce output drift?
- What does an end-to-end migration playbook look like?
- Frequently Asked Questions (FAQs)
Introduction
Swapping Claude Opus 4.8 for Claude Fable 5 in a live automation looks like a one-line change: edit the model ID, redeploy, enjoy better answers. In practice, that kind of hot swap is one of the fastest ways to break downstream systems, quietly corrupt a report, or confuse a customer.
Anthropic shipped Claude Fable 5 on June 9, 2026 as the first generally available "Mythos-class" model, and it is genuinely more capable than Opus 4.8. But more capable also means different. Its outputs will drift in shape, tone, length, JSON structure, and refusal behavior unless you actively control for it. That drift is exactly what breaks the small, fragile, important automations a business runs every day.
This guide walks through a safe way to handle a claude fable 5 migration for live work - lead qualification, email drafting, support triage, reporting, and internal tools - where even a tiny format change can cause a big downstream mess. The goal is simple: move the prompts that deserve to move, leave the rest alone, and never let a customer be the one who finds the bug. If you'd rather have someone scope the migration order for you, there's a link to book a short call at the end.
What changes when you move from Opus 4.8 to Claude Fable 5?
Before you touch a single prompt, it helps to know what's actually different under the hood. Fable 5 is not "Opus 4.8 but smarter." It's a different class of model with its own habits.
Anthropic describes Fable 5 as a public-facing version of the high-end Mythos 5 system with extra safeguards. It ships with a 1 million token context window, up to 128,000 output tokens, and a knowledge cutoff around January 2026. You can reach it through the Claude API with the claude-fable-5 model ID, plus Claude.ai, Claude Code, and the major clouds. Pricing sits at $10 per million input tokens and $50 per million output - roughly double the Opus 4.x series. From launch through June 22 it's temporarily included at no extra cost on Pro, Max, Team, and seat-based enterprise plans, after which usage needs credits or API billing. You can read the details in the launch announcement.
For a live automation, those headline specs translate into very practical effects. More context and longer outputs mean responses can overflow whatever your downstream tool expected. Higher unit cost changes the ROI math on every call. And stronger safety means different refusal and fallback behavior, which we'll cover in its own section.
There's also a quieter operational change. To support advanced safety monitoring, Anthropic now requires 30-day retention for Fable 5 and Mythos 5 traffic, even for organizations that previously had zero-retention agreements. Anthropic states the retained data is used to detect attacks and jailbreaks, not for training. If your business or your customers have strict data-retention rules, that alone can be a non-technical reason to keep certain workflows where they are.
Why is a model swap not a drop-in replacement?
Set pricing and safety aside for a moment. Even on pure behavior, changing "Opus 4.8" to "Fable 5" is rarely drop-in safe for anything non-trivial. The reason is output drift - small but meaningful differences in how the model answers that quietly break assumptions baked into your pipeline.
The most damaging kind is format and JSON drift. A lot of automations depend on the model returning strict, parseable JSON. Fable 5 might rename a key (label instead of category), add a helpful field you never asked for, omit an optional field more often, or wrap the JSON in a friendly sentence like "Here's the JSON you requested." A more capable model often tries to infer what you "really meant" and helpfully adds structure - which is exactly what shatters a brittle parser.
Length and verbosity drift is the next trap. With a bigger output budget, Fable 5 tends to write longer, add caveats, and expand bullet points into paragraphs. If a downstream system expects a short subject line, an SMS-length message, or a fixed-size summary, that extra prose blows past character limits, creates multi-line content where one line was expected, and quietly raises latency and cost.
Then there's tone and style drift. Teams spend real effort tuning Opus 4.8 to hit a brand voice - concise support replies, neutral reports, professional summaries. Fable 5 may default to a slightly more explanatory or careful tone, add hedging in sensitive areas, and phrase the same intent differently, which trips up any tool that relies on keyword matching. If some flows still run Opus 4.8 while others move to Fable 5, customers can see two different voices from the same company.
Refusals and edge-case behavior round out the list. New safeguards mean a prompt that Opus 4.8 answered cleanly might now get a structured refusal or a safety disclaimer. And because Fable 5 has a different training history, its handling of empty fields, truncated input, and ambiguous queries won't match Opus 4.8's quirks. Code that assumes "there is always a valid classification label" can break the first time a refusal arrives. None of this means Fable 5 is worse - it means the contract between the model and your code has changed, and you have to renegotiate it on purpose.
What does a Claude Fable 5 migration checklist look like?
A predictable migration has four phases: build a golden test set, pin the output format, diff old versus new, then stage and monitor the rollout.
A predictable migration has four phases: build a golden test set, pin the output format, diff old versus new, then stage and monitor the rollout. Do them in order and most surprises turn into caught regressions instead of production incidents.
How do you build a golden test set from real data?
Start by turning your current Opus 4.8 behavior into a contract you can test against. Pull a representative sample of real inputs from production logs - different customer segments and languages, the weird edge cases (empty fields, very long inputs, odd formatting), and the failure cases you've had to fix by hand before.
For each input, define an expected output. Where the output is structured, that means the exact JSON shape: keys, types, and which fields are required versus optional. Where the output is naturally variable, like an email draft, define acceptance criteria instead of one canonical string. For example: "subject line must be 70 characters or fewer, contain the product name, and use no emojis," or "JSON must validate against this schema and the classification must be one of hot, warm, or cold."
Finally, label the edge cases and any high-risk scenarios - inputs where Opus 4.8 sometimes wobbled, or domains where Fable 5's safeguards might react differently. This labeled set becomes your regression suite. Every time you change a prompt or a setting, you re-run it against both models and see exactly what moved.
How do you pin output format to stop drift?
The single best defense against claude fable 5 output drift is to stop relying on soft instructions like "please respond in JSON" and move to hard constraints wherever you can. If your platform supports schema-based structured output, use it. If it doesn't, emulate it: describe the schema unambiguously in the system prompt, give one canonical example per task, and explicitly forbid extra keys, comments, or explanations.
Here's a compact schema contract you can adapt for a lead-qualification flow:
{
"lead_score": "hot | warm | cold",
"reason": "string, 1-3 sentences, plain text, no newlines",
"follow_up": "boolean"
}
Pair that with a blunt instruction: output a single JSON object matching this schema, nothing before it and nothing after it. The more precise you are, the less room Fable 5 has to be "helpful" in ways that break your parser.
How do you diff old and new responses?
With a golden set and a pinned format, run every input through both claude-fable-5 and Opus 4.8, then compare. Validate schema adherence first - any output that fails to parse is an instant signal. Then compare distributions: is the category mix similar, are priority levels skewing higher, are reply drafts getting longer? For longer documents, check structure: does Fable 5 keep your section layout, and are its recommendations more specific while staying inside your length limits?
When you spot drift - say Fable 5 keeps adding a confidence_score field you never defined - fix it at the prompt by explicitly forbidding the extra key, then re-run the suite. Treat the diff as a loop, not a one-time check.
How do you stage the rollout safely?
Never flip 100% of traffic at once. Start with shadow mode: Opus 4.8 still serves the real workflow while Fable 5 runs silently on the same inputs in the background. Compare the two for a week or two with zero customer risk. Once shadow results look good, move to a percentage rollout - 10%, then 30%, then 70%, then 100% - watching JSON validation failure rates, response length, latency, and your real business KPIs at each step. Keep a single config flag that can route any flow straight back to Opus 4.8 if a regression shows up. That flag is what turns a scary migration into a calm one.
How do you handle refusal and fallback differences?
Fable 5's safety layer behaves differently from Opus 4.8's, and that difference deserves explicit handling rather than hope. When a request is judged high-risk in areas like cybersecurity, biology, chemistry, or model distillation, the system may block it with a structured refusal or route it through Claude Opus 4.8 as a fallback, with the answer then coming from that older model.
That has two consequences for an automation. First, some prompts that Opus 4.8 answered may now return refusals or extra safety language, so any code that assumes "there is always a valid result" needs a branch for the refusal case. Second, a single workflow might sometimes be served by Fable 5 and sometimes by Opus 4.8 through fallback, which means occasional shifts in tone or format even after you "migrated." In cloud apps users can be told when a fallback model handled their request; in the API you can see structured refusals and decide how to handle them.
The practical fix is to make refusal a first-class output in your schema. Tell the model that if it cannot comply, it should still return valid JSON - for example a status: "refused" field with a short plain-English reason - rather than free-form prose. Then your downstream code can route refusals to a human, retry with a clarified prompt, or fall back to a template, all without crashing. If you've already written a separate post or runbook on refusal and fallback, link to it here rather than rebuilding that logic from scratch; the migration only needs to make sure refusals don't silently break the pipeline.
When should you not migrate a workflow at all?
A migration is a tool, not a goal. Plenty of workflows are better off staying on Opus 4.8 or an even cheaper model, and recognizing them saves money and risk.
Leave a flow alone when a cheaper model already does the job well. Straightforward classification, routing, and templated messages often hit near-perfect accuracy once prompts and schemas are tuned, and paying double for Fable 5 buys nothing measurable. Be cautious with extremely format-sensitive, tightly coupled pipelines that lean on specific Opus 4.8 quirks - it may be smarter to redesign and harden those first, then switch models, rather than migrate a brittle thing as-is. And if compliance or legal rules demand stricter data retention than 30 days, Fable 5's retention requirement may simply rule it out for certain flows.
The right mental model is targeted upgrades, not wholesale replacement. Move the workflows where Fable 5's real strengths - long-context reasoning, subtle judgment, multi-step planning - clearly outweigh its higher cost, and leave the simple, high-volume jobs on cheaper models. A good migration often ends with a mix of models, not a single one.
Which prompt and settings tweaks reduce output drift?
Once you've decided a workflow is worth moving, a handful of practical techniques keep Fable 5's behavior stable.
System-prompt pinning is the most powerful lever. Use the system prompt to fix the role ("you are an internal tool whose output is consumed by software, not humans"), the format contract ("always output a single JSON object matching this schema, never any text outside it"), the tone ("neutral and professional, short sentences, no emojis"), and the refusal behavior ("if you can't comply, return JSON with status refused and a reason"). Because Fable 5 follows instructions well, a precise system prompt often has more influence than it did on older models - provided you're explicit.
The settings matter too. For business automation you usually want stability over creativity, so set temperature very low (often 0.0 to 0.2) and, if available, use conservative top_p and top_k to cut randomness further. That doesn't replace schemas and validation, but it makes outputs more repeatable between calls and across model versions.
Be explicit about length and structure, since Fable 5 will happily use its large output budget if you let it. Spell out limits like "subject line: 70 characters max" or "summary: three bullets, one sentence each," and apply the same constraints to each text field inside your JSON. Finally, separate reasoning from the final answer: let the model think internally if it helps, but require that the actual output be only the final JSON object or message. Standardize these patterns across similar workflows - same schema, same tone rules, same refusal contract - so the next migration, whether it's Fable 5 to some future model, has far less surface area for drift.
What does an end-to-end migration playbook look like?
To make this concrete, picture a small B2B SaaS company running three live automations on Opus 4.8: lead qualification from inbound forms, support ticket triage with suggested replies, and weekly account-health reports for customer success managers.
They start by deciding what to migrate. Lead qualification is high-volume but mostly simple and works well already, so they keep it on Opus 4.8 for cost reasons. Support triage needs better understanding of nuance, so it moves first. Account-health reports span lots of data and benefit from the 1M token context, so they migrate too. The lesson here is that the decision is per-workflow, not company-wide.
Next they build golden test sets - a few hundred real tickets paired with the Opus 4.8 output and the human agent's final reply, plus a spread of accounts with their inputs and resulting reports. Before touching Fable 5, they harden prompts and schemas while still on Opus 4.8: explicit fields, forbidden extra keys, length and tone constraints, all deployed on the old model first for a clean baseline. Then they run diff tests against claude-fable-5 on the same inputs, fixing drift at the prompt as they find it and noting any new refusals.
With the diffs clean, they turn on shadow mode while Opus 4.8 still does the real work, compare results for two weeks, and only then move to a staged rollout - 10%, 30%, 70%, 100% - with a config flag ready to revert. A month later they review ROI: Fable 5 is pricier per token, but better triage and time saved on reports more than pay for it, and lead qualification stays on Opus 4.8. No model ID swap, done carefully, ever turned into an outage.
Migrating from Opus 4.8 to Fable 5 isn't a model ID swap - it's a chance to formalize your output contracts, harden your pipelines, and be deliberate about where the extra capability and cost are worth it. Build the golden test set, pin the format, diff carefully, and roll out through shadow mode and incremental traffic, and you can upgrade without breaking a single live automation.
If you'd like help deciding which workflows to move first and in what order, book a free 45-minute AI roadmap call. We'll map your live automations, flag the risky ones, and scope a safe migration plan you can actually run.
Frequently asked questions
Quick answers on the topics covered in this article.
It's the process of moving prompts and live automations from Claude Opus 4.8 (or another model) to Claude Fable 5 while keeping output formats, tone, and downstream parsing stable. Done well, it means building a golden test set, pinning output format with schemas, diffing old versus new responses, and staging the rollout rather than swapping the model ID and redeploying.
Because a more capable model answers differently. Fable 5 can rename JSON keys, add fields you didn't ask for, write longer responses, shift tone, or return refusals where Opus 4.8 gave a clean answer. Any downstream code that assumed the old output shape can break on these changes - that's output drift.
Output drift is the set of small but meaningful differences between two models' responses to the same input: format and JSON structure, length and verbosity, tone and phrasing, refusal behavior, and edge-case handling. It's the main reason a model swap is not drop-in safe for production automations.
Stop using soft instructions like "please respond in JSON" and switch to hard constraints. Use schema-based structured output if your platform supports it, or describe the schema unambiguously in the system prompt, give one canonical example, forbid extra keys and commentary, and validate every response against the schema before your code uses it.
A golden test set is a representative collection of real production inputs paired with expected outputs or acceptance criteria, including edge cases and past failures. It turns your current Opus 4.8 behavior into a contract you can test against, so every prompt or setting change can be re-run on both models to catch regressions before customers do.
In shadow mode, Opus 4.8 keeps serving the real workflow while Fable 5 runs silently on the same inputs in the background. You compare the two with zero customer risk, confirm the new model behaves, and only then move to a staged percentage rollout. It's the safest way to validate a migration in production.
Make refusal a first-class output. Instruct the model to return valid JSON even when it can't comply - for example a status field set to refused with a short reason - so your code can route to a human, retry, or use a template instead of crashing. Also expect that some requests may be routed to Opus 4.8 as a fallback, which can shift tone or format.
Skip the migration when a cheaper model already handles the task well (simple classification, routing, templated messages), when a pipeline is so brittle it should be redesigned first, or when compliance rules conflict with Fable 5's 30-day data retention requirement. Migrate where long-context reasoning and judgment clearly justify the higher cost.
Set temperature low (often 0.0 to 0.2) and use conservative top_p and top_k for stability. Pin the role, format contract, tone, and refusal behavior in the system prompt, set explicit length limits on every text field, and require that the final output be only the JSON object with no internal reasoning included.
Sometimes. Fable 5 costs roughly double Opus 4.8, so it earns its price on long-context reasoning, nuanced judgment, and multi-step planning, but not on simple high-volume tasks. The right setup usually ends with a mix of models - Fable 5 where it clearly pays off, cheaper models everywhere else.
Share this article
Related workflows
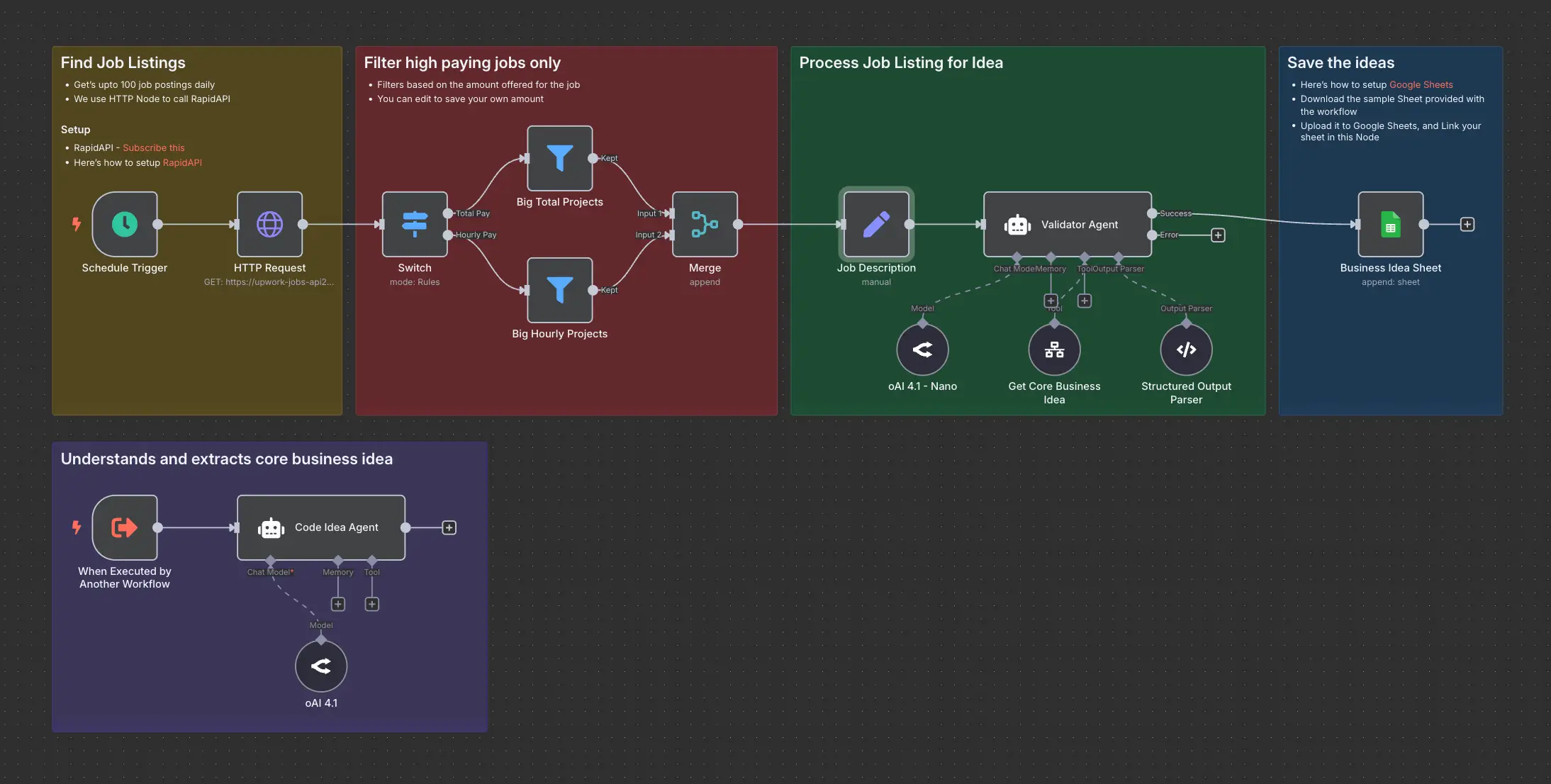
Daily Validated Business Ideas using n8n and Upwork