Claude Fable 5 Pricing: Is the 2x Over Opus 4.8 Worth It? (2026)


Table of Contents
- Introduction
- What is Claude Fable 5 and how much does it cost vs Opus 4.8?
- Is Claude Fable 5 pricing worth it for business automation?
- Where does Claude Fable 5 actually earn its 2x cost?
- When should you route to a cheaper model instead?
- Which model should you choose for each task type?
- How do you estimate cost per task before upgrading?
- How does tiered model routing cap your spend?
- When should you not adopt Claude Fable 5 at all?
- How do you decide what to upgrade first?
- Frequently Asked Questions (FAQs)
Introduction
On June 9, 2026, Anthropic shipped Claude Fable 5, the first generally available "Mythos-class" model and, by their own benchmarks, the strongest Claude yet. It is also the most expensive. At $10 per million input tokens and $50 per million output, Fable 5 costs roughly twice the current flagship, Claude Opus 4.8, which sits at $5/$25. The launch announcement leans into long-horizon, agentic, hard-reasoning work as where the new model pulls ahead.
For a small business watching token spend, that price tag sets up a simple but expensive trap: switching every workflow to the newest model "because it's better," and quietly doubling your AI bill with no change in business outcomes. Most of what small teams automate - drafting replies, classifying tickets, extracting fields, routing leads, summarizing notes - does not need a frontier model at all.
This post is the total-cost view. I'll walk through what Fable 5 costs, where the 2x premium genuinely pays off, where you should route to Haiku, Sonnet, or Opus 4.8 instead, and how to decide per workflow using a cost-per-task lens rather than vibes. If you want the broader context on why one model choice can break an automation, see why one AI model quietly breaks your business automations.
What is Claude Fable 5 and how much does it cost vs Opus 4.8?
Claude Fable 5 is Anthropic's first GA Mythos-class model, launched June 9, 2026. The API id is claude-fable-5, it offers a 1M-token input context and 128k output, and it is available on the Claude API, AWS, Google Vertex AI, and Microsoft Foundry. Anthropic positions it as state-of-the-art on most benchmarks, with the advantage growing on longer, more complex, long-horizon agentic tasks. On short or simple tasks, the gap over Opus 4.8 - and even over Sonnet and Haiku - is small.
The pricing is the headline for budget owners:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Relative to Opus 4.8 |
|---|---|---|---|
| Claude Fable 5 (standard) | $10 | $50 | 2x |
| Claude Fable 5 (Batch API) | $5 | $25 | 1x |
| Claude Opus 4.8 | $5 | $25 | baseline |
Two practical notes. First, the Batch API halves the cost to $5/$25, which matters a lot for non-urgent, high-volume jobs like overnight document processing where a few hours of latency is fine. Second, Fable 5 is free on Pro, Max, Team, and Enterprise plans through June 22, 2026, then moves to usage credits - so any "it feels amazing" testing you do this week is happening at zero marginal cost and won't reflect your real bill.
Pricing moving up is not unique to Anthropic. The trend across labs is upward: GPT-5.5 launched at roughly 2x GPT-5.4, and Gemini 3.5 Flash is pricier than the prior Flash tier. The frontier keeps getting more capable and more costly, which makes deliberate routing more valuable every release cycle, not less. For the Opus 4.8 baseline this all compares against, see what business teams should know about Claude Opus 4.8.
Is Claude Fable 5 pricing worth it for business automation?
The honest answer is: for most small-business automations, no - and for a small slice, absolutely. The mistake is treating that as one decision instead of dozens.
Here's the trap in numbers. Say you run a support inbox that drafts 8,000 reply suggestions a month, plus a classifier that tags 30,000 incoming messages, plus a weekly research agent that produces 12 deep competitor briefs. If you "upgrade everything to Fable 5," the two high-volume jobs - drafting and classification - dominate your token spend and double in cost, while delivering output that a reader cannot tell apart from Sonnet's. The one workflow that might actually benefit, the research agent, is a rounding error on volume. You'd pay the 2x premium almost entirely on the workflows that needed it least.
The capability curve is the reason. Fable 5's edge grows with task length and complexity. On a 200-token classification or a three-sentence reply draft, the difference between Fable 5 and a mid-tier model is marginal, because the task barely exercises the reasoning that justifies the price. On a multi-step research task spanning hundreds of thousands of tokens, where one wrong inference compounds across the whole run, the gap is real and can change the result.
So "is it worth it" is the wrong question at the account level. The right question is per workflow: does the quality lift on this specific task change a business outcome - a won deal, an avoided costly error, a brief you'd otherwise pay a person hours to produce - or does it just feel smarter? If it only feels smarter, it's not worth 2x.
Where does Claude Fable 5 actually earn its 2x cost?
There is a real set of jobs where Fable 5 likely earns the premium, and it's worth being concrete so you can recognize them in your own stack.
The clearest case is long-horizon agentic work: tasks where the model plans, calls tools across many steps, and has to stay coherent over a long run. When an agent has to hold context across dozens of actions, a cheaper model's small per-step error rate compounds into a failed run. A more capable model that recovers gracefully and self-checks can be the difference between an agent that finishes and one that derails halfway and needs a human to clean up.
The second case is multi-step research and analysis - competitor teardowns, synthesizing a stack of filings, building a recommendation from messy inputs. These are exactly the tasks where Fable 5's advantage grows with context length, and where a sharper answer has tangible value.
Third is complex coding and migrations: large refactors, multi-service changes, or anything where a subtly wrong implementation costs real engineering hours to catch and fix. Fourth is hard reasoning where a wrong answer is expensive - pricing logic, contract interpretation, anything touching money or compliance where the cost of one bad inference dwarfs the token cost of the better model.
Fifth is big-context document work: feeding a large corpus into that 1M-token window and needing the model to reason across all of it without losing the thread. When mistakes in that synthesis cost real money, paying more per token to reduce them is rational.
The common thread: Fable 5 earns its keep when the cost of being wrong is high and the task is genuinely hard. That's a small fraction of most SMB automation portfolios - often the hardest 10 to 20 percent - not the bulk of it.
One adoption-cost caveat worth flagging: Fable 5 ships with refusal classifiers (cyber, bio, chem, distillation) that can fall back to Opus 4.8 on flagged content, and there's no zero-data-retention option at launch. If you operate in a regulated or data-sensitive context, factor that into the decision; reliability and data handling are part of total cost, not just the per-token rate.
When should you route to a cheaper model instead?
For the everyday majority of automations, a cheaper tier wins on cost without a meaningful quality drop. The pattern is to match the model to the difficulty of the task, not to the prestige of the latest release.
Triage and classification - tagging messages, detecting intent, routing tickets to the right queue - is a job for Haiku. These tasks are short, well-defined, and run at high volume, which is the worst possible profile for an expensive model. The accuracy difference is usually negligible, while the cost difference is enormous at scale.
Drafting, standard summarization, and lead qualification belong on Sonnet. Most reply drafts, meeting summaries, and "is this lead worth a call" scores don't need frontier reasoning; they need solid, consistent output at a reasonable price. Sonnet is the workhorse for the bulk of SMB glue work - CRM updates, support drafts, content first-passes.
Reserve Opus 4.8 and Fable 5 for the hard 10 to 20 percent: the tasks identified above where complexity and the cost of error are both high. Even there, start with Opus 4.8 and only step up to Fable 5 if the harder model measurably changes the outcome. The goal isn't to avoid premium models - it's to spend premium tokens only where they convert into business value.
If you're choosing between Claude tiers and other vendors entirely, the stack-level comparison in Claude vs ChatGPT for business automation is a useful companion read.
Which model should you choose for each task type?
Here's a practical mapping of common small-business tasks to the model tier that usually makes sense, with rough relative pricing as your gut check.
Here's a practical mapping of common small-business tasks to the model tier that usually makes sense, with rough relative pricing as your gut check. Treat it as a starting point to test against your own data, not gospel.
| Task type | Recommended model | Rough relative price | Why |
|---|---|---|---|
| Message classification, intent detection, routing | Haiku | $ (cheapest) | High volume, short, well-defined |
| Support reply drafts, summaries, lead qualification | Sonnet | $$ | Solid quality at scale, most SMB glue |
| Standard content first-drafts, extraction | Sonnet | $$ | Quality lift from premium is marginal |
| Complex coding, multi-service refactors | Opus 4.8, then Fable 5 if needed | $$$ | Errors cost real engineering time |
| Long-horizon agents with many tool calls | Opus 4.8 or Fable 5 | $$$-$$$$ | Compounding errors derail cheap models |
| Multi-step research and analysis | Fable 5 | $$$$ | Edge grows with length and complexity |
| High-stakes reasoning (pricing, contracts, money) | Fable 5 | $$$$ | Cost of a wrong answer dwarfs token cost |
| Big-context document synthesis | Fable 5 (or Batch API) | $$$$ | 1M context, mistakes are expensive |
To make the choice even faster, here's a recommendation matrix in plain "choose X if you need Y" form:
| Choose this model | If you need... |
|---|---|
| Haiku | Cheap, fast, high-volume tagging and routing where accuracy is already good enough |
| Sonnet | Reliable drafts, summaries, and qualification across most of your everyday automations |
| Opus 4.8 | Strong reasoning and coding for hard tasks, at half the cost of Fable 5 |
| Claude Fable 5 | The best available output on long, complex, high-stakes work where being wrong is expensive |
| Fable 5 via Batch API | Frontier quality on non-urgent, high-volume jobs you can run with some latency at half price |
The pattern is balanced on purpose. Haiku wins on cost and speed for simple work, Sonnet wins on value for the broad middle, Opus 4.8 wins on price-to-capability for hard tasks, and Fable 5 wins on raw capability for the hardest, highest-stakes slice. No single model wins everything.
How do you estimate cost per task before upgrading?
Before you switch any workflow to Fable 5, run a back-of-the-envelope estimate. The formula is simple:
Monthly cost = (input tokens per run x input price + output tokens per run x output price) x runs per month
Work it for the same task on two models and compare. Say a support draft uses about 1,500 input tokens and 400 output tokens, and you run it 8,000 times a month.
On Sonnet (assume roughly $3/$15 per million), each run is about (1,500 x $3 + 400 x $15) / 1,000,000 = about $0.0105, so roughly $84/month. On Fable 5 at $10/$50, each run is (1,500 x $10 + 400 x $50) / 1,000,000 = about $0.035, so roughly $280/month. Same task, more than 3x the bill, for output most customers can't distinguish.
Now flip it for a research agent: 250,000 input tokens and 20,000 output tokens per brief, 12 briefs a month. On Fable 5 that's (250,000 x $10 + 20,000 x $50) / 1,000,000 = $3.50 per brief, about $42/month. If a sharper brief helps you win or keep even one deal, that spend is trivially justified - and the Batch API would halve it again if you can tolerate latency.
That contrast is the whole point. Only upgrade when the quality lift changes a business outcome, not when it merely feels smarter. The cost-per-task lens turns an emotional "newer is better" decision into a number you can defend. For a broader framework on which flows deserve investment first, see AI automation ROI: 2-3 revenue flows, not subscriptions.
How does tiered model routing cap your spend?
The most reliable way to get frontier quality where it matters without a frontier bill everywhere is tiered routing: try a cheap model first, and escalate to a more expensive one only when the task warrants it.
The pattern looks like this. A request comes in and hits a cheap model - Haiku or Sonnet - first. The system then checks a signal: the model's own confidence, a complexity score, a validation step, or whether the output passed a structured check. If confidence is high and the output is clean, you're done at low cost. If confidence is low, the task looks complex, or a validation step fails, you escalate to Opus 4.8 or Fable 5 for a second, better pass.
Done well, this means the expensive model only runs on the fraction of requests that genuinely need it - often a small share - while the cheap model absorbs the easy majority. Your average cost per task lands far below "Fable 5 on everything," and you still get top-tier output on the hard cases.
You can build this routing in an orchestration layer like n8n, Make, or a small bit of code in front of the API. The key design choices are the escalation signal (confidence threshold, complexity heuristic, or a validator) and a cap so a runaway task can't escalate endlessly. It's worth noting that premium models don't replace this orchestration - they're reasoning nodes inside it. If you're weighing the orchestration tools themselves, n8n vs Make vs Zapier for AI workflow automation compares the options.
When should you not adopt Claude Fable 5 at all?
Some situations argue against Fable 5 even before you reach the cost-per-task math.
Skip it for high-volume, simple workflows. If your automation is thousands of short, well-defined runs - classification, tagging, routing, simple extraction - the premium model adds cost without adding outcome. This is where the doubling hurts most and helps least.
Skip it for data-sensitive work where the launch limitations bite. With no zero-data-retention option at launch, anything bound by strict data-handling rules may not clear your compliance bar yet, regardless of capability. The refusal classifiers that fall back to Opus 4.8 on flagged content can also introduce behavior you didn't plan for in regulated domains.
Skip it for budget-constrained automations where "good enough, reliably" beats "best, expensively." If a workflow is already delivering acceptable results on Sonnet, upgrading is spending money to chase a lift you may not be able to measure or monetize.
And skip it as a default. The failure mode isn't choosing Fable 5 for a hard problem - it's choosing it everywhere out of habit. Treat the frontier model as a deliberate, justified exception, not the standing default for new automations.
How do you decide what to upgrade first?
If you only take one thing from this post: don't make the model choice account-wide. Make it per workflow, ranked by the cost of being wrong and the volume of runs.
A simple way to start. List your automations. For each, note the monthly run count, roughly how hard the task is, and what a wrong answer actually costs you. The high-volume, low-stakes, low-complexity jobs stay on Haiku or Sonnet - that's most of your list. The low-volume, high-stakes, high-complexity jobs are your Fable 5 candidates - usually a short list. Then estimate cost per task on both tiers and only upgrade where the better output maps to a real outcome.
That ranking exercise is exactly the kind of thing that's faster with a second pair of eyes, because the trap is so easy to fall into when the new model genuinely is impressive in a demo.
If you want help ranking which workflows - if any - justify the Fable 5 premium and designing the tiered routing to cap spend, that's what a 45-minute AI roadmap call is for. We'll look at your actual automations, estimate cost per task, and leave you with a clear list of what to route where, so you capture the upside of the frontier without doubling your bill on the workflows that never needed it.
Frequently asked questions
Quick answers on the topics covered in this article.
For most small-business automations, no - the everyday tasks like drafting, classification, and summarization don't need a frontier model, and the 2x cost buys little outcome. Fable 5 is worth it for a small slice of hard, high-stakes work: long-horizon agents, complex research, and reasoning where a wrong answer is expensive. Decide per workflow, not account-wide.
Fable 5 is $10 per million input tokens and $50 per million output - roughly twice Opus 4.8, which is $5/$25. The Batch API halves Fable 5's cost to $5/$25 for non-urgent jobs that can tolerate some latency.
It pays off on long-horizon agentic tasks, multi-step research and analysis, complex coding and migrations, hard reasoning where errors are costly, and big-context document work. Its advantage grows with task length and complexity, so the gain is largest exactly where being wrong is most expensive.
Use Haiku for triage, classification, and routing; Sonnet for drafting, standard summarization, and lead qualification; and most CRM and support glue. Reserve Opus 4.8 and Fable 5 for the hardest 10 to 20 percent of tasks. On short, simple work the quality gap is small while the cost gap is large.
Multiply input tokens per run by input price plus output tokens per run by output price, then multiply by runs per month. Run the same math on a cheaper model for the same task and compare. Only upgrade when the quality lift changes a real business outcome, not when it merely feels smarter.
Tiered routing sends each request to a cheap model first, then escalates to a premium model only on low confidence, high complexity, or a failed validation check. The expensive model runs on a small fraction of requests, so average cost stays low while hard cases still get top-tier output. You can build it in n8n, Make, or a thin layer of code.
It's free on Pro, Max, Team, and Enterprise plans through June 22, 2026, then moves to usage credits. Because that testing is at zero marginal cost, it won't reflect your real per-token bill, so don't let the free window drive a permanent everywhere-upgrade decision.
Fable 5 offers a 1M-token input context and 128k output, with the API id claude-fable-5. It's available on the Claude API, AWS, Google Vertex AI, and Microsoft Foundry.
Yes. Skip it for high-volume simple workflows where the premium adds cost without outcome, for data-sensitive work given there's no zero-data-retention option at launch, and for budget-constrained automations already working well on Sonnet. Its refusal classifiers can also fall back to Opus 4.8 on flagged content.
No. Fable 5 is a reasoning model that sits inside your automation as a node. Triggers, retries, idempotent writes, escalation logic, and cross-system glue still belong in your orchestration layer, which is also where you'd implement tiered routing to control cost.
Share this article
Related workflows
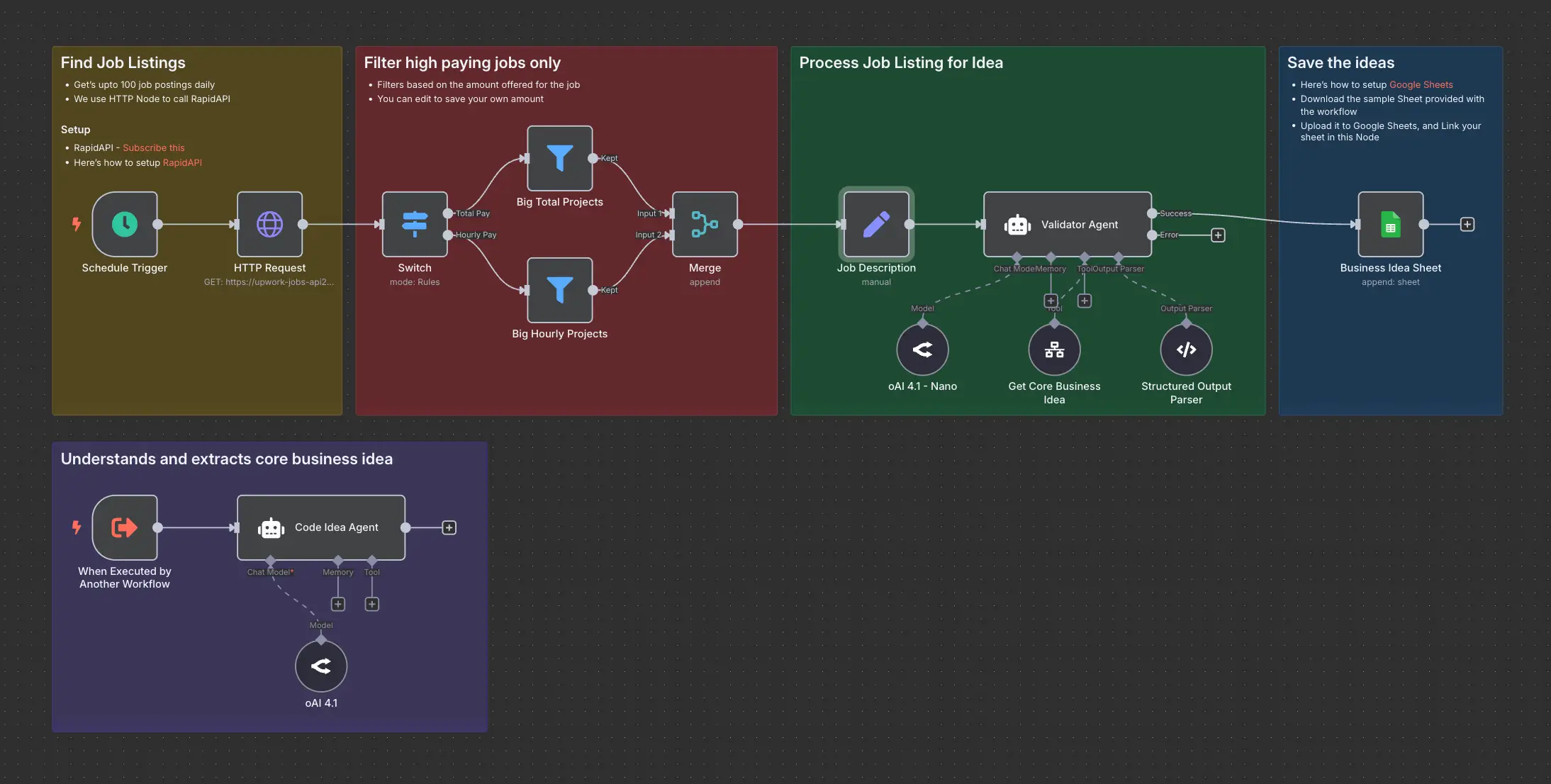
Daily Validated Business Ideas using n8n and Upwork