Claude Opus 4.8 Released: What Business Teams Should Know (2026)


Table of Contents
- Introduction
- What is Claude Opus 4.8 and what changed on May 28, 2026?
- How does Claude Opus 4.8 compare to Opus 4.7 on benchmarks and real work?
- What are effort control and dynamic workflows in Claude Opus 4.8?
- What does Claude Opus 4.8 cost on the API, fast mode, and GitHub Copilot?
- Where can you use Claude Opus 4.8 today?
- When should a small business upgrade to Claude Opus 4.8?
- What honesty improvements matter if you ship Opus 4.8 to production?
- How do you pilot Opus 4.8 without another round of AI seat sprawl?
- Frequently Asked Questions (FAQs)
Introduction
Anthropic shipped Claude Opus 4.8 on May 28, 2026. If you are running Claude Pro, Max, Team, or Enterprise, or building on the Claude API, this is the flagship upgrade over Opus 4.7 - not a rebrand, but a push on coding, long-running agents, and calmer judgment under load.
This post is a practical read for business and engineering leads: what changed, what it costs, where it runs, and when an upgrade beats hype. It is not a benchmark leaderboard. For how Claude fits next to ChatGPT inside real stacks, see Claude vs ChatGPT for business automation: stack-first pick. For why chat tabs rarely become production systems, see why your team's Claude tab never reaches production.
What is Claude Opus 4.8 and what changed on May 28, 2026?
Claude Opus 4.8 is Anthropic's top generally available model for hard reasoning, long-horizon coding, and high-autonomy work. The launch post frames it as building on 4.7 with stronger benchmarks and a more reliable collaborator - same list price, available the same day on claude.ai, the Claude Platform, major clouds, and GitHub Copilot.
Three themes matter for operators:
- Long-horizon coding - better behavior across very long contexts, fewer painful compactions, and stronger recovery when context does get summarized.
- Effort you can steer - explicit effort levels on claude.ai and in Claude Code, plus adaptive thinking so simple turns stay cheap and hard turns get depth.
- Platform features beside the weights - dynamic workflows in Claude Code (research preview), cheaper fast mode (2.5x speed, now three times cheaper than on prior Opus fast mode), and API ergonomics like system entries inside the messages array for mid-run instruction updates without breaking prompt cache.
Developers call the model with claude-opus-4-8 on the Claude API. Context is up to 1M tokens on the Claude API and partner clouds (with lower caps on some surfaces, such as 200K on Microsoft Foundry at launch).
How does Claude Opus 4.8 compare to Opus 4.7 on benchmarks and real work?
Anthropic published a side-by-side comparison of Opus 4.8, Opus 4.7, GPT-5.5, and Gemini 3.1 Pro on coding, reasoning, computer use, knowledge work, and finance-agent tasks.
Anthropic published a side-by-side comparison of Opus 4.8, Opus 4.7, GPT-5.5, and Gemini 3.1 Pro on coding, reasoning, computer use, knowledge work, and finance-agent tasks. The chart below is from their May 28 launch post; scores are vendor-reported until independent labs publish their own runs.
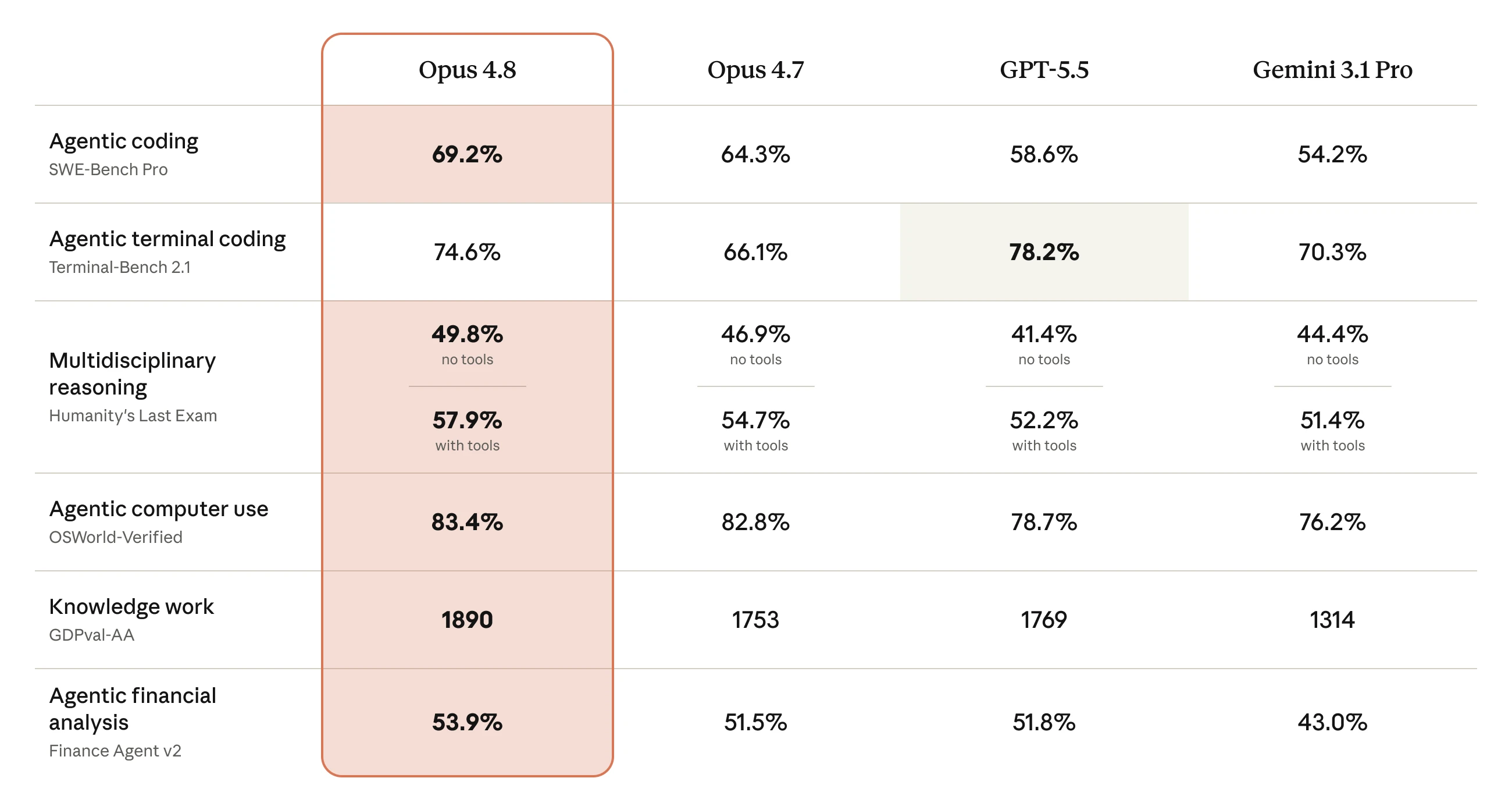
Image: Benchmark comparison chart from Anthropic, Introducing Claude Opus 4.8, May 28, 2026. Methodology and additional evals are in Anthropic’s Claude Opus 4.8 materials.
Headline numbers from that table:
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Agentic coding (SWE-Bench Pro) | 69.2% | 64.3% | 58.6% | 54.2% |
| Agentic terminal coding (Terminal-Bench 2.1) | 74.6% | 66.1% | 78.2% | 70.3% |
| Reasoning, no tools (Humanity's Last Exam) | 49.8% | 46.9% | 41.4% | 44.4% |
| Reasoning, with tools (Humanity's Last Exam) | 57.9% | 54.7% | 52.2% | 51.4% |
| Agentic computer use (OSWorld-Verified) | 83.4% | 82.8% | 78.7% | 76.2% |
| Knowledge work (GDPval-AA) | 1890 | 1753 | 1769 | 1314 |
| Agentic financial analysis (Finance Agent v2) | 53.9% | 51.5% | 51.8% | 43.0% |
For business readers, three patterns stand out. Opus 4.8 leads on most agentic and knowledge-work rows versus 4.7 and the named rivals. GPT-5.5 still wins Terminal-Bench 2.1 in Anthropic’s chart (78.2% vs 74.6%). And 4.8 is a clear step up from 4.7 on coding and reasoning, not a sideways refresh.
Partner quotes and early GitHub Copilot testing still matter for feel in real repos. Benchmarks tell you where Anthropic aimed; your pilot tells you if your stack benefits.
GitHub's Copilot changelog describes a clear step in code understanding, generation, and large-codebase navigation. Copilot rolls out gradually; admins on Business and Enterprise must enable the model policy.
Dynamic workflows (research preview in Claude Code) let Opus 4.8 plan large jobs, spin up many parallel subagents in one session, and verify output before reporting back. Anthropic's example is codebase-scale migration across hundreds of thousands of lines with the existing test suite as the bar. That is not "faster autocomplete"; it is orchestrated engineering work - useful only if you have tests, branch protection, and someone who owns merges.
If your team will wire models into CRM, support, or billing flows rather than live only in an IDE, the orchestration layer still matters. Opus 4.8 does not replace n8n, Make, or native CRM automation; it is a reasoning node inside those graphs.
What are effort control and dynamic workflows in Claude Opus 4.8?
Effort control is the headline UX change on claude.ai and in Cowork: a control next to the model picker that trades speed and rate-limit burn for depth of reasoning.
Effort control is the headline UX change on claude.ai and in Cowork: a control next to the model picker that trades speed and rate-limit burn for depth of reasoning. Higher effort means more internal thinking; lower effort answers faster and consumes limits more slowly.
Opus 4.8 defaults to high effort, which Anthropic says balances quality and experience on coding (similar token spend to 4.7 default, better results). In Claude Code you can push xhigh or max for hard or long async jobs. Anthropic also raised Claude Code rate limits to match higher token use at those levels.
Adaptive thinking (when enabled) spends extra reasoning only when the task warrants it. That helps mixed workloads - lots of easy turns with occasional monster tasks - without paying flagship depth on every message.
For business users, effort control is a cost and governance knob, not a party trick. Route routine drafting to lower effort or to Sonnet; reserve Opus 4.8 high or max effort for refactors, incident analysis, contract-heavy summaries, and agent runs that touch production systems.
What does Claude Opus 4.8 cost on the API, fast mode, and GitHub Copilot?
Standard API pricing is unchanged from Opus 4.7:
| Mode | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Standard | $5 | $25 |
| Fast (2.5x throughput) | $10 | $50 |
Anthropic still advertises up to 90% savings with prompt caching and 50% with batch processing on the Claude Platform. Opus 4.8 also lowered the minimum cacheable prompt length to 1,024 tokens, so more day-to-day prompts can benefit from cache economics than on 4.7.
On GitHub Copilot, Opus 4.8 launched with a 15x premium request multiplier until usage-based billing lands (GitHub noted June 1, 2026 in their changelog). Treat Copilot Opus as a targeted developer subsidy, not the default for every repo.
Chat plans (Pro, Max, Team, Enterprise) get Opus 4.8 in the product UI; API and cloud buyers pay per token. None of that removes the need to measure cost per completed workflow, not per excited demo.
Where can you use Claude Opus 4.8 today?
As of the May 28 launch window:
- claude.ai - Pro, Max, Team, Enterprise with effort control.
- Claude API - model id
claude-opus-4-8. - Claude Code - dynamic workflows (preview), higher effort tiers, improved long sessions.
- Cloud - AWS Bedrock, Google Cloud Vertex AI, Microsoft Foundry (check each provider's context limits).
- GitHub Copilot - Pro+, Business, Enterprise where enabled and rolled out.
If you already standardized on another model in production agents, Opus 4.8 is an upgrade path, not a forced migration. Run parallel on one workflow, compare error rate, revision count, and human minutes saved, then switch the routes that justify the premium.
When should a small business upgrade to Claude Opus 4.8?
Upgrade or pilot Opus 4.8 when 4.7 or Sonnet is clearly the constraint:
- Complex engineering - multi-service refactors, large legacy repos, migrations you could not finish with prior models.
- Agentic workflows - tools must fire reliably across long runs (support triage, research agents, internal ops bots).
- Large documents - contracts, filings, or knowledge bases where compaction used to break threads.
- High-stakes drafts - you need the model to flag uncertainty, not bluff through thin evidence.
Skip a blanket upgrade when most work is short email, social copy, or simple Q&A. Cheaper tiers still win on volume. If you are early in automation maturity, rank flows first - AI automation ROI: 2-3 revenue flows - before you add flagship tokens everywhere.
Anthropic's own positioning is blunt: Opus is for tasks no prior model could handle and where performance is worth paying for. That is the right filter for SMB budgets.
For internal knowledge and onboarding without another SaaS seat, Claude Projects for SOPs is still the lighter path; Opus 4.8 inside Projects raises the ceiling on hard questions inside those corpora.
What honesty improvements matter if you ship Opus 4.8 to production?
Early testers and Anthropic's system card narrative emphasize honesty and self-checking: Opus 4.8 is less likely to let defects in its own code pass without comment and more likely to surface uncertainty on thin evidence.
Early testers and Anthropic's system card narrative emphasize honesty and self-checking: Opus 4.8 is less likely to let defects in its own code pass without comment and more likely to surface uncertainty on thin evidence. That does not replace tests, code review, or legal sign-off.
Operational habits that pair well with 4.8:
- Ask for failure modes and confidence on outputs that touch customers or money.
- Keep human approval on writes to CRM, billing, and public replies.
- Log model version and effort level when you debug bad runs.
If you are moving from chat experiments to APIs and webhooks, honesty gains only matter inside a harness that records inputs, tool results, and approvals. The model got better; your process still defines trust.
How do you pilot Opus 4.8 without another round of AI seat sprawl?
A sane pilot looks like this:
- Pick one painful workflow - e.g. a single repo, a support tier-2 queue, or a weekly ops report - not "everyone switch models Monday."
- Run parallel - same prompts on 4.7 (or Sonnet) and 4.8 for two weeks; track time-to-done, rework, and escalations.
- Tune effort - default high for coding; try medium on mixed chat; reserve max/xhigh for async jobs.
- Turn on caching - stable system prompts and long shared context blocks (manuals, schemas) so 4.8's 1K cache floor actually saves money.
- Decide per route - API routes, Copilot repos, and claude.ai power users do not all need the same tier.
When you are ready to map which flows deserve Opus, Sonnet, or orchestration outside Anthropic entirely, a short paid session at /roadmap-call ranks build order on your real stack before you buy more seats or tokens.
Anthropic also teased Mythos-class models under Project Glasswing with stronger cyber safeguards - not GA for everyone yet. Opus 4.8 is the production-grade step you can ship this week; Mythos is the "watch the system card" horizon.
Frequently asked questions
Quick answers on the topics covered in this article.
Anthropic announced Claude Opus 4.8 on May 28, 2026, with same-day availability on claude.ai, the Claude API, partner clouds, and GitHub Copilot (gradual rollout).
Use claude-opus-4-8 on the Claude API and compatible platforms.
Standard API pricing is the same as 4.7: $5 per million input tokens and $25 per million output tokens. Fast mode is $10 / $50 per million input/output tokens for about 2.5x throughput.
Effort control lets you choose how much internal reasoning Claude spends per reply on claude.ai and Cowork. Higher effort improves hard tasks but uses more tokens and rate limit; lower effort is faster and lighter.
Dynamic workflows (research preview) let Opus 4.8 plan large tasks, run many parallel subagents in one session, and verify results before returning - aimed at very large code changes such as repo-wide migrations.
Yes. GitHub made Opus 4.8 generally available on May 28, 2026 for Copilot Pro+, Business, and Enterprise where admins enable it. Early access used a 15x premium request multiplier ahead of usage-based billing.
Anthropic and early partners report better tool calling, long-context stability, and judgment on hard coding and agent tasks. Anthropic cites roughly four times lower rate of unmentioned flaws in the model's own code versus 4.7 in their evaluations.
Usually no. Use Opus 4.8 for the hardest workflows; keep Sonnet or earlier tiers for high-volume, low-risk work. Measure cost per completed outcome, not model prestige.
Up to 1 million tokens on the Claude API and several cloud partners; some surfaces (e.g. Microsoft Foundry at launch) list lower caps such as 200K - check your provider's docs.
No. Opus 4.8 is a reasoning model inside apps, IDEs, and APIs. Triggers, idempotent writes, retries, and cross-system glue still belong in your CRM, help desk, and orchestration layer.
Share this article
Related workflows
Daily Validated Business Ideas using n8n and Upwork
Domain Name Generator n8n workflow using ScrapingDog