n8n vs Make vs Zapier: Which AI Workflow Tool Fits Your Team?


Table of Contents
- Introduction
- Why are AI workflows harder to automate than classic integrations?
- How does Zapier handle AI steps for non-technical teams?
- What makes Make strong in n8n vs Make comparisons for visual AI pipelines?
- When does n8n win for RAG, agents, and self-hosted models?
- How do Zapier tasks, Make operations, and n8n executions affect AI costs?
- Which AI workflow automation tools connect best to LLMs and vector stores?
- What do self-hosting and governance mean for n8n vs Zapier on sensitive data?
- How do you debug runs when an LLM step goes wrong?
- n8n vs Make vs Zapier: which platform fits your team?
- Recommendation matrix: choose X if you need Y
- How should you pilot before you commit?
- Frequently Asked Questions (FAQs)
Introduction
If you are comparing n8n vs Make or n8n vs Zapier for production AI workflows, you are not picking a logo. You are picking who can change prompts safely, where customer data may flow, and how painful billing gets when every run touches five LLM calls plus a vector lookup.
All three are mature AI workflow automation tools. They diverge sharply once you add retrieval, branching on model output, and agent-style tool loops. This guide is an honest comparison as of mid-2026: pricing mechanics, AI features, governance, and a choose X if you need Y matrix. Full disclosure: I use n8n in client work, but teams I advise still run Zapier and Make where they fit. No single vendor wins every scenario.
Why are AI workflows harder to automate than classic integrations?
Classic automation is mostly deterministic: trigger, map fields, call an API, done. AI workflows insert probabilistic steps in the middle. A model classifies intent, retrieves chunks from your knowledge base, maybe calls a CRM tool, then drafts a reply. That means more branches, more retries, more things to log when output drifts.
You also pay twice: platform usage (tasks, operations, or executions) and LLM API spend. A workflow that looked cheap at 500 runs per month can break budgets at 50,000. The platforms below differ in how they count those runs, which matters more for AI than for simple two-step Zaps.
How does Zapier handle AI steps for non-technical teams?
Zapier optimizes for speed and breadth. Non-technical users can stand up "when form submits, summarize and post to Slack" in minutes. The catalog spans thousands of apps, which is still hard to beat when you need obscure SaaS connectors without writing HTTP clients.
AI landed as layers on the Zap model: natural-language Zap building, AI Actions for summarize/classify/generate, and separate products for chatbots and agents with their own pricing. For light AI inside business automations (enrich a lead, tag support tickets, draft email copy), Zapier remains the lowest-friction option.
The friction shows when you need multi-step reasoning, custom RAG ingestion, or agents that dynamically pick tools. You often end up calling an external agent API from a Zap and treating it as a black box, or you hit task-based billing where every action in a run counts. A trigger plus five actions, run ten thousand times, is not ten thousand platform units on Zapier. It is a multiple of that. AI steps multiply the bill quickly.
n8n vs Zapier for AI is less "which has OpenAI" and more "who maintains the graph when volume and compliance grow."
What makes Make strong in n8n vs Make comparisons for visual AI pipelines?
Make (formerly Integromat) targets power users who think in systems. Scenarios are visual graphs with routers, iterators, and aggregators. You see the whole pipeline on one canvas, which helps when AI sits between many transforms (clean HTML, embed, write to vector DB, call LLM, route by confidence).
Make ships native modules for major LLM APIs and generic HTTP for everything else. n8n vs Make often comes down to team skill and hosting:
| Dimension | Make | n8n (typical) |
|---|---|---|
| Primary user | Technical ops, integrators | Developers, platform engineers |
| Hosting | Managed cloud (SOC 2, EU options) | Self-host or n8n Cloud |
| Billing unit | Per module (operation) | Per execution (cloud) or infra (self-host) |
| AI depth | Strong structured pipelines | Strong RAG, agents, local models |
Make is an excellent middle ground for AI-enhanced business processes (content ops, enrichment, classification at scale) when you want more control than Zapier without running your own stack. It is cloud-only for most teams, so data residency is "trust Make's region," not "keep embeddings on our VPC."
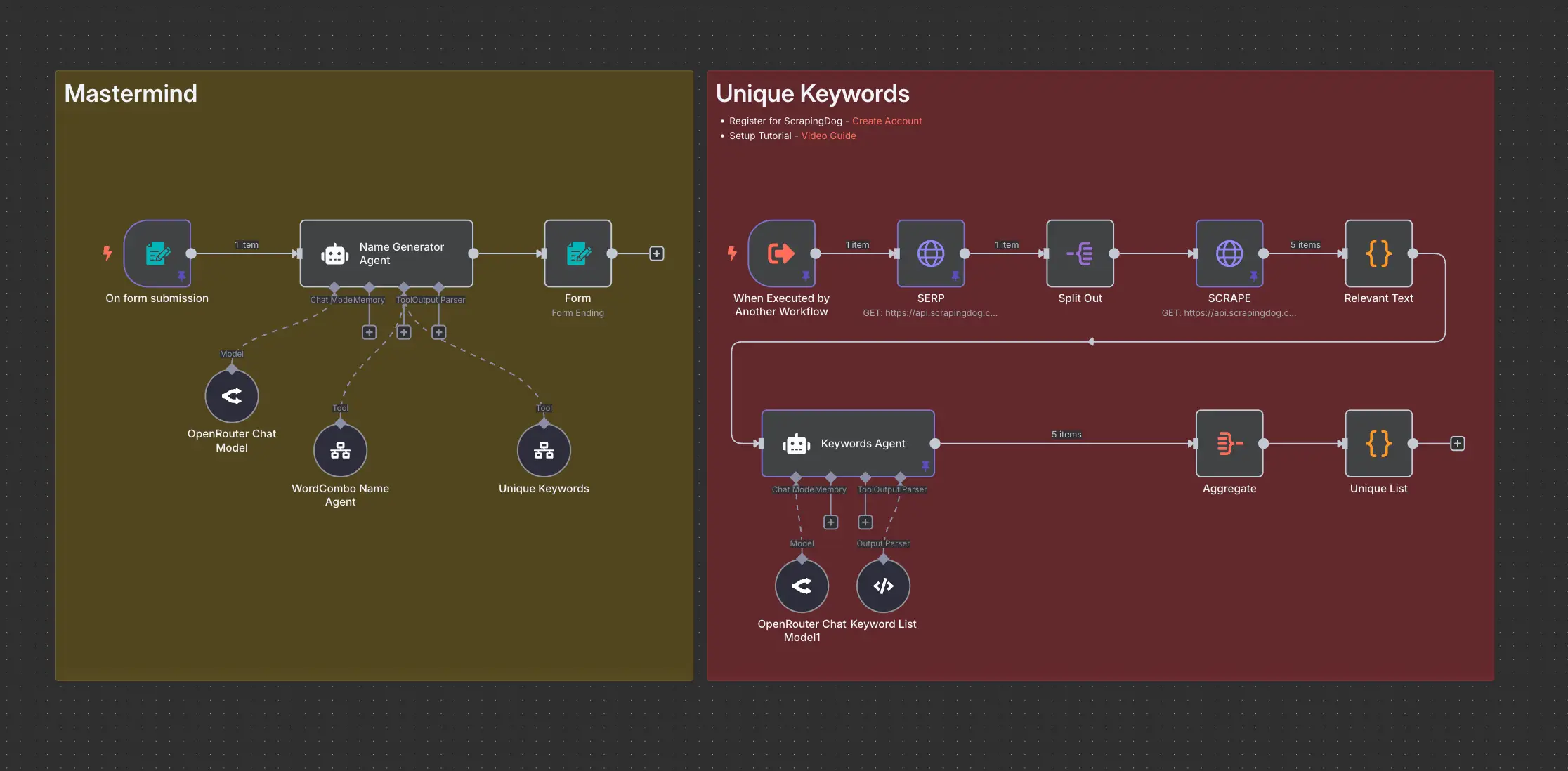
When does n8n win for RAG, agents, and self-hosted models?
n8n is source-available and can be self-hosted. The UI is low-code, but the product assumes you will write expressions, JavaScript in Function nodes, and HTTP to anything undocumented. For AI, that shows up as LangChain-style nodes, vector DB connectors (depending on edition/community packs), Ollama and other local model paths, and workflows where one execution can include many nodes but one billable run on n8n Cloud.
RAG (ingest, chunk, embed, index, query at runtime) is tedious on Zapier unless an external service owns the heavy lifting. Make can orchestrate ingestion and query paths cleanly. n8n is built for teams that want the pipeline inside their environment, especially with self-hosted vector stores and internal APIs.
Agentic patterns (plan, tool call, observe, loop) are possible on all three, but n8n maps naturally to "LLM node decides branch, tool nodes are ordinary integrations." Self-hosting means agents can call internal services without exposing them to a multi-tenant SaaS. The tradeoff is operational: someone patches Docker, handles secrets, and wires logs to your existing stack.
I reach for n8n when a client needs data residency, high-volume multi-step AI, or custom model endpoints. I do not reach for it when marketing needs five quick Zaps next Tuesday with zero engineering time.
How do Zapier tasks, Make operations, and n8n executions affect AI costs?
Pricing is the silent killer of AI automation. Approximate mental models (verify current plan pages before you budget):
| Platform | What you pay for | AI-heavy example |
|---|---|---|
| Zapier | Tasks (often each action) | 1 trigger + 5 actions = 6 tasks per run |
| Make | Operations (each module run) | 8 modules = 8 operations per run |
| n8n Cloud | Executions (one per workflow run) | 20 nodes still = 1 execution |
| n8n self-host | Infrastructure + your time | No per-step platform fee |
At low volume with one or two AI steps, differences are modest. At tens of thousands of runs with branching and multiple LLM calls, Zapier is usually the most expensive per run, Make is better per step but still scales with module count, and n8n Cloud or self-host tends to win on complex graphs because one run is one execution.
Always model LLM tokens separately. A cheaper orchestrator does not fix an unbounded gpt-4 loop.
Which AI workflow automation tools connect best to LLMs and vector stores?
All three connect to major cloud LLMs (OpenAI, Anthropic, Google, and others). Differences show at the edges:
- Zapier: widest SaaS catalog; AI Actions for common patterns; advanced agent/RAG often externalized.
- Make: strong visual LLM modules plus HTTP for custom APIs; good for structured multi-branch AI ops.
- n8n: fewer prebuilt apps than Zapier, but HTTP + code + community nodes cover internal and niche APIs; best fit for self-hosted models, OpenAI-compatible gateways, and custom vector DBs.
If your stack is "fifteen SaaS tools and light summarization," Zapier or Make may ship faster. If your stack is "internal Postgres, Qdrant, and a fine-tuned endpoint in the VPC," n8n is usually less fighting.
What do self-hosting and governance mean for n8n vs Zapier on sensitive data?
Zapier is cloud-only with solid baseline compliance (SOC 2, encryption, GDPR-oriented controls, SSO on enterprise tiers). Many companies are fine sending operational data through it. Regulated or highly sensitive prompts and embeddings often are not.
Make is also managed cloud with enterprise features (SOC 2 Type II, SSO, SCIM, EU hosting). Governance is stronger than Zapier for complex scenarios, still not self-host.
n8n lets you keep workflow definitions, execution logs, and secrets in your infrastructure. You can forward metrics and logs to Prometheus, Elasticsearch, or your SIEM. n8n Cloud adds managed security for teams that skip ops but accept vendor hosting.
For AI, governance questions include: who can edit system prompts, are retrieval sources logged, and can you replay "what context did the model see?" All three offer run history; self-hosted n8n integrates deepest with how platform teams already audit systems.
How do you debug runs when an LLM step goes wrong?
You need step-level inputs and outputs, not just "workflow failed." Zapier exposes task history suitable for simple flows. Make's execution inspector shines on branched scenarios: click a module, see JSON in flight. n8n provides similar per-node logs; self-hosted teams often export them to central logging.
For AI specifically, log retrieved chunks, model version, and redacted prompts where policy allows. Without that, you are guessing whether bad output was the model, stale index, or wrong router branch.
n8n vs Make vs Zapier: which platform fits your team?
Think on three axes: team skill, workflow complexity and volume, security posture.
Zapier fits non-technical owners, simple AI helpers (classify, summarize, enrich), and shops that prioritize integration count over graph depth. It strains on heavy RAG, dynamic agents, and high-frequency multi-step runs.
Make fits integrators and ops leads who want visual complexity without owning servers. Strong for content pipelines, routing, and medium-to-high volume AI ops in the cloud.
n8n fits engineers building AI workflow automation as infrastructure: RAG inside the VPC, agents calling internal tools, local models, predictable execution pricing. It asks for deploy and maintain effort if self-hosted.
Recommendation matrix: choose X if you need Y
| If you need... | Lean toward... |
|---|---|
| Fastest path for non-devs, few AI steps, huge SaaS catalog | Zapier |
| Visual complex branching, cloud-only, better $/step than Zapier at volume | Make |
| Self-host, strict data residency, RAG + agents in your stack | n8n |
| Lowest platform cost for 15-step AI graphs at high run count | n8n (Cloud or self-host) |
| EU enterprise cloud without running infra | Make |
| "We will never run Docker" and AI is light | Zapier or Make |
Plain-language rules:
- Choose Zapier if simplicity and citizen builders beat depth.
- Choose Make if you outgrew Zapier's linear feel but are not ready to operate n8n.
- Choose n8n if you are building AI infrastructure, not just automating a spreadsheet.
How should you pilot before you commit?
- Pick one production-shaped workflow (not a toy): e.g., support ticket triage with retrieval, or lead enrichment with classification.
- Estimate monthly units on each vendor's model (tasks, operations, executions) plus token spend.
- Score governance: data residency, prompt change control, replayability.
- Build on two finalists for a week and compare time-to-debug when the model hallucinates.
In most evaluations I run, the pilot makes the choice obvious faster than feature checklists.
Frequently asked questions
Quick answers on the topics covered in this article.
Not universally. n8n is usually better for complex, high-volume, or self-hosted AI (RAG, agents, internal APIs). Zapier is better when non-technical users need simple AI steps across many SaaS apps quickly. Compare n8n vs Zapier on volume, compliance, and graph complexity, not headline features.
Make charges per module run (operation); n8n Cloud charges per workflow execution regardless of node count. Multi-step AI pipelines often cost less per run on n8n at scale; Make sits between Zapier and n8n for many scenarios. Self-hosted n8n trades license fees for infrastructure and engineering time.
"Best" depends on team skill and constraints. Zapier leads for ease and integrations; Make for visual complex cloud workflows; n8n for developer-led AI systems, self-hosting, and heavy RAG or agents. Many organizations use more than one.
Yes, often by combining AI Actions with external vector services or dedicated agent products. Full ingestion-to-query pipelines and tight agent loops are usually easier on Make or n8n unless you keep RAG outside Zapier.
Make is primarily a managed cloud platform. For strict on-prem or VPC-only AI data, n8n self-host (or custom code) is the usual answer in this trio.
Execution-based pricing on complex graphs, self-hosting, local models via Ollama, and flexible HTTP or code nodes for internal systems. Teams already running platform engineering get governance wins by wiring n8n into existing observability.
Low-volume, few-step automations; marketing or ops owners without dev support; need for the largest prebuilt integration list. Summarize, classify, and route use cases shine here.
Often n8n (especially self-hosted) when runs include many steps per execution. Zapier tends to be most expensive per run at scale; Make is typically cheaper than Zapier but more step-sensitive than n8n Cloud.
Use the same workflow on a pilot, count platform units and tokens, test failure debugging, and list non-negotiables (SSO, residency, who edits prompts). Do not choose from a feature matrix alone.
Yes. Common pattern: Zapier or Make for business-owned light automations, n8n for core AI platform workflows. Standardize secrets, logging, and prompt versioning across both.
Share this article
Related workflows
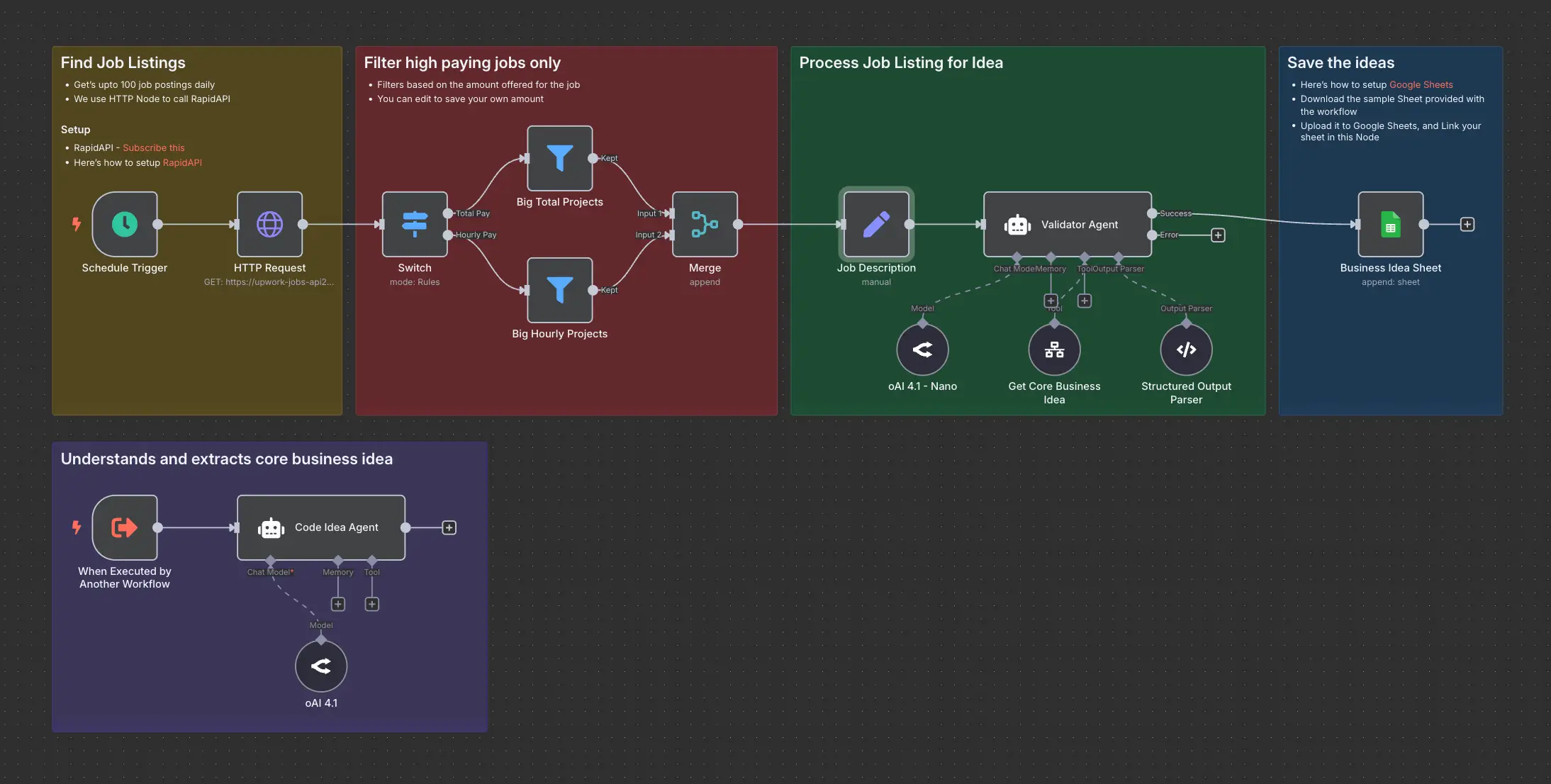
Daily Validated Business Ideas using n8n and Upwork
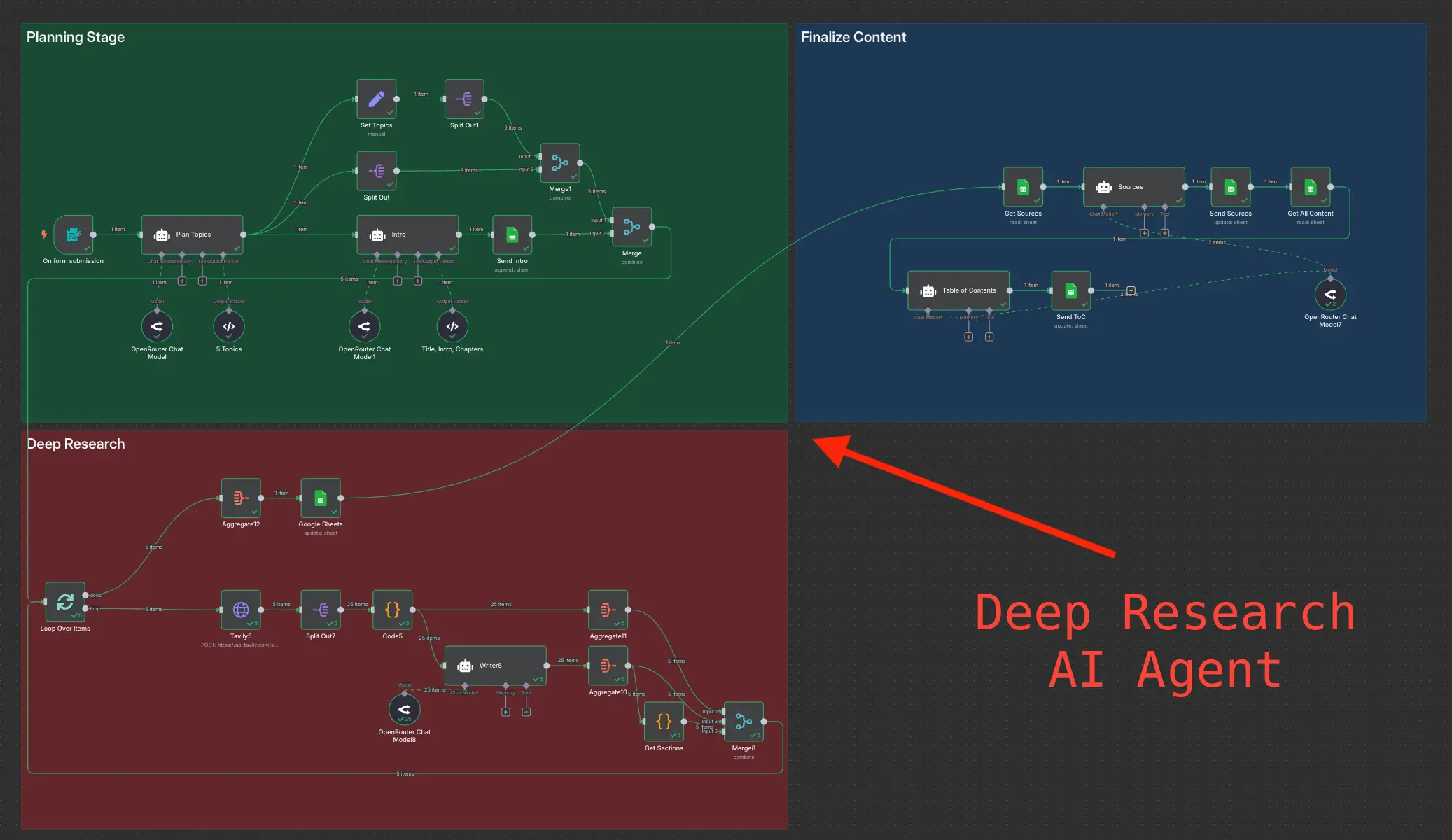
Deep Research using n8n automation to generate report using Tavily